
 [English]Am 19. Juli 2024 kam es weltweit zu zahlreichen Störungen an IT-Systemen. Der Betrieb an Flughäfen stand, Banken konnten nicht mehr arbeiten, Züge fielen aus, und Firmen schickten ihre Mitarbeiter nach Hause (z.B. Tegut), weil die IT-Systeme nicht mehr gingen. Es war aber kein Cyberangriff, sondern das gleichzeitige Auftreten zweier Fehler – unabhängig voneinander, die zum Ausfall von Funktionen führte. Einmal gab es einen Ausfall der Microsoft-Cloud, rund um Microsoft 365 und die betreffenden Dienste. Und es gab ein fehlerhaftes Update für eine Sicherheitslösung des US-Anbieters CrowdStrike, die Windows-Systeme mit einem BlueScreen abstürzen ließen. Hier nochmals eine kurze Nachbereitung.
[English]Am 19. Juli 2024 kam es weltweit zu zahlreichen Störungen an IT-Systemen. Der Betrieb an Flughäfen stand, Banken konnten nicht mehr arbeiten, Züge fielen aus, und Firmen schickten ihre Mitarbeiter nach Hause (z.B. Tegut), weil die IT-Systeme nicht mehr gingen. Es war aber kein Cyberangriff, sondern das gleichzeitige Auftreten zweier Fehler – unabhängig voneinander, die zum Ausfall von Funktionen führte. Einmal gab es einen Ausfall der Microsoft-Cloud, rund um Microsoft 365 und die betreffenden Dienste. Und es gab ein fehlerhaftes Update für eine Sicherheitslösung des US-Anbieters CrowdStrike, die Windows-Systeme mit einem BlueScreen abstürzen ließen. Hier nochmals eine kurze Nachbereitung.
IT-Systeme, auch im KRITIS-Bereich, ausgefallen
Es hörte sich dramatisch an, was mir am 19. Juli 2024, in den frühen Vormittagsstunden, aus der Leserschaft berichtet wurde. Blog-Leser Michael meinte in einer kurzen Mitteilung "Irgendwas ist los in der Welt… Flughafen BER und Palma stehen wohl komplett". Lesermeldungen erreichten mich anschließend per Mail und über Facebook sowie auf X. Auf X schrieb mir jemand "Microsoft hat gerade wohl richtige Probleme. Siehe Twitter unter Microsoft die Beiträge. BSODs. Hat wohl was mit Crowdstrike zu tun.".
Viele Ausfälle weltweit
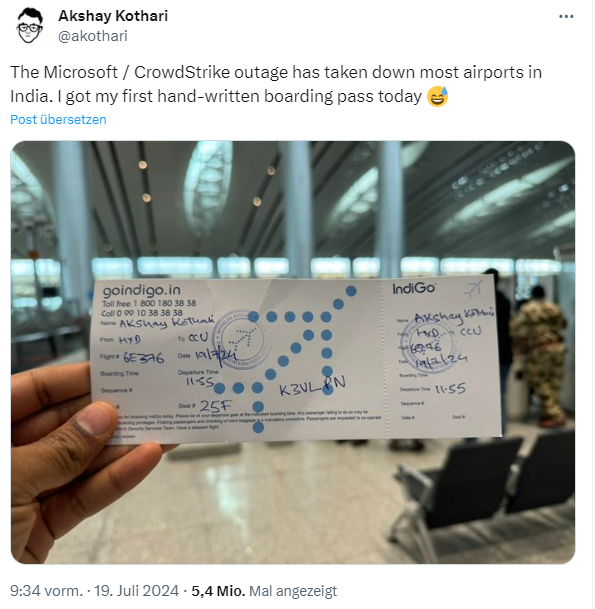
Den Meldungen im Radio entnehme ich, dass es auch die IT kritischer Infrastrukturen (KRITIS) getroffen habe – Flughäfen gehören dazu. In weiteren Posts wurde ich von Lesern informiert, dass die Infrastruktur am Flughafen in Berlin zur Zeit "down sei". Auf X hat mir ein Leser nachfolgenden Tweet zukommen lassen – auf den meisten Flughäfen Indiens steht alles – der Passagier hat eine handgeschriebene Bordkarte bekommen.
Der Sohn meiner Nachbarin wollte für eine Woche mit Familie in die USA – ich habe sie zum Flughafen Frankfurt weg fahren sehen. Eben die Information bekommen, dass die Passagiere schon im Bus saßen und zum Flugzeug auf dem Vorfeld unterwegs waren. Dann kam die Meldung "alles zurück" – die sitzen jetzt fest. Die Familie sitzt jetzt in Frankfurt im Hotel und erfährt Samstag, wie es weiter geht.
Der Artikel hier schreibt, dass Flughäfen, Züge, Rundfunksender etc. betroffen sind. Bei n-tv meldet man, dass auch Tankstellen und Banken betroffen sind. Es waren nicht nur deutsche Flughäfen betroffen – ich habe auch Meldungen gesehen, dass Kliniken betroffen sind und Operationen abgesagt wurden. Laut heise musste das Universitätsklinikum Schleswig-Holstein alle für den heutigen Freitag geplanten Operationen an ihren Standorten in Kiel und Lübeck absagen.
In diesem Artikel schreibt heise zudem, dass die Volksbanken, Sparda Banken, Sparkasse und die Deutsche Bank teilweise Probleme mit der Erreichbarkeit der Webseiten haben. Die Allianz, die Telekom sowie Vodafone seien laut Störungsmeldungen teilweise nicht erreichbar gewesen. Bei mehreren Einzelhändlern fielen die Kassensysteme aus.
Da auch für Amazons Web Services (AWS) Ausfälle gemeldet wurden, sind auch Mercedes und die Continental AG betroffen. Das Gleiche gilt für Fluggesellschaften Turkish Airlines, KLM, Lufthansa, Ryanair, schreibt heise. Mir ist unklar, was auf CrowdStrike und was auf Microsoft 365 und die nachfolgend beschriebenen, technische Störungen zurückzuführen ist.
Auch die Washington Post hat hier eine Zusammenfassung der Ausfälle veröffentlicht. Die Kollegen von Bleeping Computer haben hier weitere Beispiels aus den USA und welitweit zusammen getragen – da geht momentan wenig, selbst Feuerwehren und Polizei sind betroffen.
Bitlocker fällt Administratoren auf die Füße
In diesem BlueSky-Post heißt es, dass der CrowdStrike-Fix manuell für jeden einzelnen Rechner bereitgestellt werden muss. Im Beitrag Ausfall von Microsoft 365 und weltweite Störungen – wegen CrowdStrike-Update, was zum BSOD führt? hatte ich aber ausgeführt, dass es auch andere Workarounds gibt. Allerdings lassen sich diese nicht immer anwenden – ein Leser wies mich auf diesen Tweet hin, wo man liest:
Too bad everything I have is Bitlocker encrypted, including the Window Server hosting the Bitlocker recovery keys! Having to type a 48 digit number on 5K machines, my carpel tunnel will scream and my eyes will melt.
Da steht jemand vor dem Schlamassel, dass an 5.000 Maschinen ein Bitlocker-Key zum Booten gefordert wird. Der obige Post gehört zu diesem Thread und der Blog-Leser merkt an:
Letztendlich lassen sich die Systeme gar nicht via Patch entstören. Das ist händische Arbeit. Viel Spaß, wenn wenige Leute tausende verteilte Systeme betreuen. Der Workaround ist auch nur anwendbar, wenn man z.B. den Bitlocker Entsperrschlüssel hat…
Das klingt nach ziemlich viel Wochenend-Arbeit und die Systeme dürften länger ausfallen, wenn den Administratoren nicht noch ein Trick einfällt.
Zwei unabhängige Ereignisse
Zu Beginn sah es so aus, dass die Microsoft-Cloud-Probleme und das fehlerhafte CrowdStrike-Update miteinander zu tun hätten. Aber es sind zwei unterschiedliche Ereignisse, die zufällig zeitgleich bzw. sich überlappend abspielten.
- Von der US Cybersicherheitsfirma CrowdStrike war ein Update für ihr Sicherheitssystem ausgerollt worden, welches auf Windows als Host für Abstürze mit BlueScreen sorgte. Das bewirkte, dass zahlreiche IT-Systeme weltweit offline gingen. Ich habe die bisher bekannten Details im Blog-Beitrag Ausfall von Microsoft 365 und weltweite Störungen – wegen CrowdStrike-Update, was zum BSOD führt? zusammen getragen.
- Bei Microsoft führte dagegen eine Konfigurationsänderungen an Azure zu Problemen mit der Cloud. In Folge waren bei Microsoft 365 die Dienste (OneDrive, SharePoint etc.) nicht mehr erreichbar und aus die Apps aus dieser Suite funktionierten nicht mehr. Ich habe diesen Sachverhalt inzwischen im Beitrag Weltweiter Ausfall von Microsoft 365 (19. Juli 2024) aufbereitet.
Die Folgen dürften für einige Firmen gravierend sein, ich gehe davon aus, dass die weltweiten IT-Störungen zu Schäden in Milliardenhöhe führen. Wenn nur 1 Million Systeme betroffen waren und pro System 1.000 Euro Umsatzausfall zu verzeichnen sind, wäre dies bereits eine Milliarde. Ausgefallene Flüge, stehende Züge etc. dürften mehr Schaden als 1.000 Euro verursachen. Ergänzung: Bei Focus Online geht man von tagelangen Ausfällen und Milliarden Schäden aus. Zitiert wird Professor Alan Woodward von der Universität Surrey aus dem Telegraph.
Weckruf, die IT-Infrastruktur zu überdenken
Ich hatte es bereits erwähnt: Der Umstand, dass selbst kritische Infrastruktur wie Flughäfen oder Kliniken betroffen waren, sollte für die IT-Verantwortlichen ein deutlicher Weckruf sein. Der in Sachen Cybersicherheit aktive Prof. Dennis Kipker schrieb auf X:
Absoluter Worst Case und Grund, warum wir der Cloud kein unbegrenztes Vertrauen schenken sollten! Von KRITIS über Staat bis zu Industriebetrieben. Bestes Beispiel dafür, dass das Mantra "IT aus der Steckdose" ein Holzweg ist!
Er spielt darauf an, dass immer mehr IT-Leistungen in die Cloud ausgelagert werden und niemand mehr richtig durchsteigt, was wo passiert. Ich würde es so ausdrücken: Es werden ständig grundlegende Prinzipien der IT-Ausfallsicherheit verletzt – ein "Single Point of Failure" sorgt dafür, dass an Flughäfen nichts mehr geht, Tankstellen streiken, Züge nicht mehr disponiert werden können, Kassensysteme beim Einkauf streiken, und die Hälfte der Firmen nicht mehr arbeitsfähig ist.
Die Welt ist mit einem "blauen Auge" davon gekommen. Man stelle sich vor, es hätte einen Lieferkettenangriff auf CrowdStrike gegeben und statt eines fehlerhaften Updates wäre Malware eingeschleust worden, die dann eine Killsoftware oder Ransomware nachlädt. Wann erfolgt ein Nachdenken der verantwortlichen CIOs, dass es so nicht weiter gehen darf? Wenn ein entschlossener Cyber-Akteur so etwas per Lieferkettenangriff hin bekommt, kann er die Welt in den digitalen Abgrund stürzen. Oder wie seht ihr das?
Ähnliche Artikel:
Weltweiter Ausfall von Microsoft 365 (19. Juli 2024)
Ausfall von Microsoft 365 und weltweite Störungen – wegen CrowdStrike-Update, was zum BSOD führt?
Wieso weltweit zahlreiche IT-Systeme durch zwei Fehler am 19. Juli 2024 ausfielen
CrowdStrike-Analyse: Wieso eine leere Datei zum BlueSceen führte
Nachlese des CrowdStrike-Vorfalls, der bisher größten Computerpanne aller Zeiten









>>> Wann erfolgt ein Nachdenken der verantwortlichen CIOs,
Dann – und nur dann – wenn die Verursacher richtig Bluten müssen – also mal kurz 100 Milliarden Euro Strafzahlung durch MS zu leisten ist und das im Zweifel mehrfach. Die Investoren müssen Tränen in den Augen haben, wenn eine Tech Firma Scheiße im Sicherheitsbereich fabriziert. Es muss also den Investoren weh tun – richtig übel – denn dann stehen die den CIOs auf den Füßen…
Das wird beim Thema KRITIS zusehends problematischer, da Unternehmen nur noch versichert werden, wenn sie genau so eine Lösung einsetzen. Das Problem an der Sache ist, dass den IT-Verantwortlichen die Hände gebunden sind. Der Konzern entschließt ein solches Tool einzusetzen, bzw. muss dies tun, um versichert zu werden. Die IT-Verantwortlichen stoßen da auf Taube Ohren und können nichts dagegen tun.
"Der Umstand, dass selbst kritische Infrastruktur wie Flughäfen oder Kliniken betroffen waren, sollte für die IT-Verantwortlichen ein deutlicher Weckruf sein."
Totale Zustimmung! Ich wünsche mir wirklich, man würde im IT-Bereich endlich genauso konsequente Maßnahmen ergreifen, wie man das schon vor langer Zeit nach den eindringlichen Warnungen der Wissenschaft vor den schwerwiegenden Folgen des Klimawandel getan hat.
> …konsequente Maßnahmen…
LLLoooLLL
"Die Welt ist mit einem "blauen Auge" davon gekommen."
Ein Blaues Auge geht ja in ein paar tagen wieder weg.
So ähnlich wird es bei den Verantwortlichen auch diesmal sein, es zählt nur der Gewinn.
Leider läuft es gefühlt schon immer so.
In einer Woche spricht 'eh niemand mehr davon.
Ein Hoch auf die Wurstigkeit der Menschen.
Ja, das bestätigt leider meine Befürchtungen…
Cloud da, Cloud dort,… und KI nicht vergessen.
So ganz kann ich dem nicht ganz zustimmen. Wenn dies durch ein fehlerhaftes Signaturupdate/Heuristikupdate war, wird es schwierig im Wettrennen schnelle Sicherheitsupdates bereit zu stellen. Und das kann auch mit OnPrem Sicherheitssoftware passieren, die auch ihre Signaturen von draußen holt. Ein testen derer (egal ob Hersteller oder man selbst) bringt einen immer in Zeitverzug und benötigt Personal. Wenn man das hochrechnet auf die Häufigkeit solcher Vorfälle (kann mich nur an McAffee in Verbindung mit XP an was ähnliches erinnern) und dagegen 24/7 Reaktionsfähiges Personal vorhalten müsste, wird der Ausfall immer noch günstiger sein. Ich kenne auch niemanden der seine Standbysysteme mit komplett anderer Herstellersofware betreibt auf unterschiedlicher DB Architektur. Das fängt schon bei Hardware an, selbst die müsste man diverse betreiben und würde eine IT letztlich absolut unadministrierbar (Nutzen-Kosten-Faktor) machen.
Völlig richtig.
Das ist ein Katz und Mausspiel, hat mit Cloud erstmal nichts zu tun und auch schwer anders realisierbar, wenn es wirtschaftlich bleiben soll. Ohne solche Software und SIEM und KI Lösungen und voll automatisierten Updates sind aktuelle Bedrohung nicht mehr in der Fülle an Millarden Logereignissen händelbar. Und das zum testen kaum Zeit bleibt, wenn man vorn sein möchte:
https://www.heise.de/news/Bericht-Angreifer-missbrauchen-Proof-of-Concept-Code-innerhalb-von-22-Minuten-9802283.html …
Das nennt man Risikomanagement.
Egal was ist und kommt, es hilft nur ein gutes Disaster&Recovery Management. Man kann sich nicht zu 100% gegen jede erdenkliche Vorfälle schützen.
Hier muss ich zum Teil widersprechen, wenn es um das Thema Wirtschaftlichkeit geht.
Ich habe in meiner Laufbahn viele Infrastrukturen gesehen, die mit Tools und Diensten überfüllt sind und wo die IT-Abteilungen mehrheitlich reagieren statt zu agieren. Überall sieht man fatale Abhängigkeiten und in einzelnen Unternehmen habe ich Lösungen gesehen, die solche Vorkommnisse geradezu beflügeln. Es gibt nicht nur das Cloud Computing, sondern z. B. auch das Edge Computing.
In den Debatten zum Thema Wirtschaftlichkeit werden aber allzu oft nur zwei Lösungen diskutiert: On-Premises oder Off-Premises alias "Cloud" (natürlich extern, weil "angeblich" günstiger).
Würde man die Infrastruktur selbstkritisch betrachten und die damit verbundenen Kosten ordentlich durchkalkulieren, was bei einem Cloud-only-Ansatz auf externer Seite nahezu unmöglich ist, hätten wir womöglich eine bessere Betriebsstabilität.
OnPrem spiel ich die Backups wieder ein und bin unter 30 min wieder online!
OnPrem kann ich die Leitungen nach aussen auch mal aufs Minimum zurückschrauben, weil die internen Prozesse trotzdem laufen… wenn alles in der Cloud ist hast du Pech gehabt Cloud Down Unternehmen down.
Was den so lange?
Wohl noch Kaffee getrunken und eine Schnitte gemacht.
hier ca 500 Systeme lokal , 50 hat es erwischt aber etwas Fleissarbeit und fertig.
Könnet man scripten aber mit testen geht das auch nicht schneller.
Übel sind alle Notebooks mit Verschlüsselung.
Die müssen alle in der Zentrale bei uns per Hand wieder aufgemacht werden.
Weil er keine Ahnung hat mal wieder Quatsch erzählt.
Die Leute verstehen nicht, das KRITIS-Systeme nicht in die Cloud gehören, sondern im Gegenteil sogar in eine von der Außenwelt isolierte Umgebung.
Die Cloud scheint verlockend und einfach, aber solche Vorfälle wie heute zeigen, wie kritisch man mit der Cloud umgehen sollte.
Was wäre passiert, wenn die Cloudsysteme z.B. von einer fremden Macht erfolgreich angegriffen worden wären?
Das hat man dann nicht an einem Wochenende wieder am laufen!
Isolierte Systeme dagegen lassen sich nicht von außen angreifen, da braucht man physischen Zugang.
Das ist ein Armutszeugnis an Unprofessionalität von CrowdStrike und zeigt auf, wie einfach es ist, die IT weltweit lahm zu legen … es bleibt zu hoffen, dass dies keinem feindlich gesinnten Widersacher gelingt, so ein Unternehmen zu kapern und einen solchen Einfluss zu nehmen … aber vielleicht war das nur ein Beta-Test …
Ich hab' so ein Grinsen im Gesicht…
Als der Cloud Hype los ging – so Mitte der Nuller-Jahre – dachte ich mir: genau so etwas wird irgendwann passieren.
Und, "blaues Auge…" – irgendwann passiert es wieder.
Ich sage JEDEN TAG, dass diese Dinge passieren können und werden.
Und ich ernte bei jedem dieser Gespräche ungläubige Kuh-Augen, Unverständnis und erlebe Leute, die sich lieber verziehen anstatt darüber nachzudenken.
Langweilig!
Ob auch welche die aktuell offenbar grenzenlose Abhängigkeit von der "US Cybersicherheitsfirma CrowdStrike"erkennen?
"Man stelle sich vor, es hätte einen Lieferkettenangriff auf CrowdStrike gegeben…"
Hallo in die Runde. Viele Kommentare verstehe ich, aber teilweise wird in den Kommentaren hier und im ersten Post auch vieles ausgeblendet was nunmal leider der heutigen Realität entspricht.
Lieferkettenangriff in Bezug auf ein malöses Windows Update wäre ja nicht anders als dieses Desaster hier. Auch bei Linux-Systemen ist man mit der XZ-Backdoor an einem weltweiten Desaster gerade so vorbeigeschlittert was lange keiner gesehen hat.
Was also tun? Alles lokal hosten und sich abschotten? Gerne, kann mir einer dazu die mir fehlenden Experten / Expertinnen als Mitarbeiter stellen um eine Hochverfügbarkeit und eine Vertretung für alles bereitzustellen? Vielleicht wachsen die bei euch auf den Bäumen, aber bei vielen Aussagen hier macht man es sich auch einfach etwas zu leicht.
Und natürlich muss man dann irgendwann im Security-Bereich an irgendeiner Stelle sagen: Ja dir Anbieter X vertraue ich, weil ich gar keine andere Möglichkeiten mehr habe und überall Ressourcen fehlen. Bei CrowdStrike ging das nun mächtig schief. User mit anderen EDR/MDR-Systemen sind nochmal davongekommen dafür aber vielleicht nächstes Mal mit dabei…
Was sind die realen alternativen bei stark begrenzten Ressourcen und Anforderungen die es zum Überleben umzusetzen gilt? Allen Usern den Internetzugriff verrammeln? Viele Geschäftsprozesse wären damit erledigt. Ein explizites Whitelisting oder ähnliches wäre wieder Ressourcentechnisch völlig idiotisch und ebenfalls nicht 100%ig sicher (wieder z.B. die Lieferkettengeschichte). Bei vielen Firmen werden sicher falsche Prioritäten gesetzt, nicht aber bei allen. Generelles Verteufeln bringt doch auch nichts. Die Gegebenheiten sind oft komplexer als dass man hier in Stammtischmanier "ich habs ja immer gesagt" die Lösung für alles hätte.
Die Welt wird immer komplexer und uns drohen immer weitreichendere Desaster, aber ich glaube nicht, dass die Lösung für dieses Probleme in den Kommentarspalten hier zu finden sind…
Nun ja,
alternative Angebote, bei denen man wenig bis gar kein eigenes Personal braucht, gibt es,
z.B. von 'unabhängigen' IT-Service-Providern.
Diese werden jedoch durch unfaire Lizenz-Politik künstlich (Dank an VMWare, Citrix, Microsoft, u.s.w.) technisch und preislich Markt-untauglich gemacht, bis praktisch kein Kunde sie mehr will.
Wer von Euch weiß, was z.B. MS SPLA-Lizenzen gegenüber MS 365 mehr kosten?
Das 6-8 fache!
Aber warum ist Mehl plötzlich teurer als der fertige Kuchen?
Mann könnte es auch als 'Indirekten Zwang' in die Hersteller-Cloud werten – ein Schelm, der … dabei denkt.
Ist es wirklich eine gute Idee alles in die Big-Tech-Cloud zu schieben, oder wäre ein Teppich aus vielen (kleineren) Service-Providern nicht eine deutlich stabilere Alternative?
Ja, da geht auch mal einer drauf, wird angegriffen oder macht einen Fehler – aber dann steht eben NICHT die ganze Welt.
> kann mir einer dazu die mir fehlenden Experten /
> Expertinnen als Mitarbeiter stellen um eine
> Hochverfügbarkeit und eine Vertretung für
> alles bereitzustellen? Vielleicht wachsen die
> bei euch auf den Bäumen, aber bei vielen
> Aussagen hier macht man es sich auch einfach
> etwas zu leicht.
Wenn man anständig bezahlt bekommt man Personal mit der notwendigen Expertise.
Klar, Cloud scheint auf den ersten Blick billig. Ist sie aber nicht. Und da kann ich das Geld doch gleich in vernünftiges Personal investieren.
Tja das fehlen der Experten hat man ja selbst verschuldet… also nicht jammern sondern anfangen wieder ordentlich auszubilden… Außerdem ist der Expertenmangel auch kaum ein Mangel an realen Personen, sondern eher der Mangel ordentliche Gehälter zu zahlen! Tja nen Experten hält man nunmal nicht mit Mindestlohn und nen Obstkorb.
Tja mit Vogel Strauß Politik: Kopf in den Sand stecken kommst du da nicht weiter! Nicht jammern, anpacken…
Obstkorb? Bin schon froh über kostenloses Leitungswasser.
Verstehe nicht, was hier das Cloud Bashing soll. Defekte Pattern gab es schon vor zig Jahren. Das Problem waren damals schon fehlende Tests. Ergo kann es auch andere Hersteller treffen, wenn dort keine Qualitätssichernde Prozesse vorhanden sind. Ergo können auch klassische OnPrem Umgebungen betroffen sein.
bei einem klassischen OnPrem ist aber nur dessen Nutzer betroffen bzw. kann diese mit vernünftigem Personal auch reparieren.
Bei so einer "Cloud" sind Tausende/Millionen Nutzer betroffen und müssen sich alle darauf verlassen, dass der Anbieter dieser "Cloud" das Problem behebt.
Sehr interessante Analyse von "The Morpheus Tutorials" ->
https://www.youtube.com/watch?v=j3ms4rVl9nU
Warum IT-Security so schlecht läuft
Es gibt übrigens auch eine Lösung die betroffene CrowdStrile Datei zu entfernen ohne den Bitlocker Key zu wissen.
Sollte vielleicht noch ergänzt werden.
1. Cycle through BSODs until you get the recovery screen.
2. Navigate to Troubleshoot>Advanced Options>Startup Settings 3. Press "Restart"
4. Skip the first Bitlocker recovery key prompt by pressing Esc
5. Skip the second Bitlocker recovery key prompt by selecting Skip This Drive in the bottom right
6. Navigate to Troubleshoot>Advanced Options>Command Prompt
7. Type "bcdedit /set {default} safeboot minimal", then press enter.
8. Go back to the WinRE main menu and select Continue.
9. It may cycle 2-3 times.
10. If you booted into safe mode, log in per normal.
11. Open Windows Explorer, navigate to C:\Windows\System32\drivers\Crowdstrike
12. Delete the offending file (STARTS with C-00000291*, .sys file extension)
13. Open command prompt (as administrator)
14. Type "bcdedit /deletevalue (default} safeboot", then press enter.
15. Restart as normal, confirm normal behavior.
Ich kann diesen Prozess nicht beurteilen, aber mir scheint, Punkt 14 enthält einen (Klammerfehler}.
Bei Punkt 13 kommt dann das nächste kleine Problem. Nennt sich LAPS. Wenn man überhaut soweit kommt.
Wenn ich in WinRE das Recht habe, die Boot Sequenz trotz Verschlüsselung zu ändern, mit
bcdedit /set {default} safeboot minimal
dann sollte es eigentlich auch möglich sein, das wieder rückgängig zu machen mit
"bcdedit /deletevalue {default} safeboot"
in sofern läge das erste Problem doch schon bei 7, oder?
Anyway.
ich bin völlig konstaniert das so eine Änderung der Boot Sequenz ohne Bitlocker Keys recovery möglich ist.
Aber nun gut. Microsoft hat die Profis, und die werden schon wissen, wie sie dieses Henne-Ei Problem zu lösen ist.
Und immerhin muß hier physikalisch eine Tastatur angeschlossen werden.
Und wenn sich wer fragte,warum Server immer noch einen PS/2 Tastatur bieten sollte klar sein.
Damit kann man, obwohl das USB system im Passwort geschützt en BIOS/UEFI abgeschaltet ist, immer noch eine Tastatur anschließen…
ja, das könnte gehen.
im Prinzip startet man das kaputte Windows ohne den BSOD-Treiber, löscht ihn dann weg (rennamen)
und bootet dann wieder normal. Aber beim booten wird der BSOD-Treiber nicht mehr gefunden und kann nicht gestartet werden.
Der Gag ist halt, das man die Abfrage des Keys ignorieren kann, weil man das Bootverhalten im unverschlüsselten Teil ändert.
Hm, könnte man nicht auch mit gedrückter Shift taste ins WinRE kommen,
Achso, der wirklich paranoide Admin hat natürlich keine WinRE Portion eingerichtet… geht das denn über einen USB Notfall Stick?
Einige Anmerkungen dazu:
1) Crowdstrike ist eine Firma, die laut Wikipedia noch keinen einzigen Dollar Gewinn gemacht hat in ihrer 6- bis 7-jährigen Firmengeschichte. Trotzdem ist diese Firma über 1 Mrd. US-Dollar an der Börse wert.
2) Wenn ich als Firma derartig wichtige Software-Systemkomponenten für große Anbieter (in dem Falle Microsoft) bereitstelle, muss ich mir eigentlich bewusst sein, dass alle Updates meiner Software auf Herz und Nieren geprüft werden müssen – d.h. auch auf unterschiedlichen Betriebssystemen mit unterschiedlichster Konfiguration – und was das für Konsequenzen haben kann, falls das nicht ordnungsgemäß läuft. (Man bekommt manchmal das Gefühl, dass höchstens noch Alpha-Tests gemacht werden, und die Kunden als eigentliche Beta-Tester fungieren oder Beta-Tests und Ausrollen an die Kunden parallel laufen.)
3) Aus der chemischen Industrie kenne ich es, dass die Rechner des Prozessleitsystems und der Sicherheitsfunktionen inkl. der Rechner mit der Konfigurationssoftware dieser Systeme komplett vom Internet getrennt laufen. Das ist dort absoluter Minimal-Standard – ganz einfach aus dem Grund, damit sich niemand in die Systeme einhacken kann.
das ist nicht nur in der Chemie Branche so… sondern in jeder Branche wo es Produkthaftung gibt… wo du bei Fehlern mal eben Millionenstrafen zahlst.
Nur eben in der IT/Softwarebranche nicht, da gibt es keine Produkthaftung und deswegen kann jeder dahergelaufener Arsch machen was er will.
Solange das so ist wird sich auch nie was ändern.
Würde ich so in meiner Firma arbeiten säße ich längst im Knast und meine Firma wäre pleite. Tja in der IT gehts.
ich darf daran erinnern,das MS seine Tester rausgeschmissen hat
und neulich einen Bug fabrizierte, der nur auf in der "non English" installierten Maschinen passierte…da dort nicht getestet…
Man wurde zwar gewarnt,ein deutsches Windows als Basis zu installieren,aber wenn die Firmen Policy einer deutschen Firma das vorschreibt macht es der Admin, oder sollte er kündigen?
uns lehrte man einst:
Die teuerste Art Qualität in ein Produkt zu bringen ist möglichst spätes oder gar kein Test.
Außerdem sollte man Qualität niemals in ein Produkt hineintesten sondern konstruieren.
"Aus der chemischen Industrie kenne ich es, dass die Rechner des Prozessleitsystems und der Sicherheitsfunktionen inkl. der Rechner mit der Konfigurationssoftware dieser Systeme komplett vom Internet getrennt laufen. Das ist dort absoluter Minimal-Standard – ganz einfach aus dem Grund, damit sich niemand in die Systeme einhacken kann."
Ja. Und es ja auch nicht nötig, da es niemand wagen wird ein Update einzuspielen…
Und natürlich werden die USB ports deaktiviert.
Es wurde schon beobachtet, das Operatoren sich die langweilige Nachtschicht mit Spielen auf dem Steuer Rechner vertrieben hatten..installiert über die CD/DVD oder USB.
Das fiel nicht sofort auf, weil keine Filesystem Validierung erfolgte (wer rechnet denn mit so etwas?)
Heute mit Embedded Windows kein Problem.
Dank COW fällt das auf, und der Müll ist mit einem einfachen Reboot entsorgt da niemanden die Änderung confirm hat.
jetzt sind wir aber weit genug weg, smzrigt aber, das Windows (Enterprise/IOT) sich automatisch gegen so etwas schützen kann
(dreimal in eine BSOD gebootet, und automatisch wird die letzte Funktionierende Shadow Kopie gebootet.
Das hat Microsoft ziemlich gut gemacht. Nur fehlt das Wissen und wohl eher die Zeit das in der Praxis anzuwenden.
Dieser und jeder andere BSOD crash ließe sich "trivial" verhindern.
Enterprise Versionen werden ja wohl der Normal Fall sein, auch wenn die ein paar Mark mehr kosten.
"Entschuldigt diesen langen Brief,aber ich hatte keine Zeit einen kurzen schreiben" soll Blaise Pasqual mal gesagt haben.
Das Leben könnte so sein, ohne User.
edit:
Jeder andere BSOD crash nach einem Update…
und es fehlt u.a. das Wort "schön"
Was Du oben beschreibst erinnert sehr an Stuxnet.
Da war es auch so, daß die Steuerungen der Uran-Zentrifugen im Iran (Siemens S7 mit passendem Prozeßleitsystem unter Windows) nicht mit dem Internet verbunden waren.
Der Angriffsweg ist bis heute nicht offengelegt, aber vermutlich war es so, daß ein Geheimagent unter Einsatz seines Lebens einen USB-Stick mit dem entsprechenden Wurm und unter Ausnutzung des Autorun-Bugs in das System einschleuste, woraufhin die Zentrifugen die einzelnen Uranisotope immer wieder durchgemischt haben statt sie säuberlich zu trennen.
"jetzt sind wir aber weit genug weg, smzrigt aber, das Windows (Enterprise/IOT) sich automatisch gegen so etwas schützen kann
(dreimal in eine BSOD gebootet, und automatisch wird die letzte Funktionierende Shadow Kopie gebootet.
Das hat Microsoft ziemlich gut gemacht. Nur fehlt das Wissen und wohl eher die Zeit das in der Praxis anzuwenden."
Die besagte Funktion kenne ich schon aus Windows XP aus dem Wiederherstellungsdialog.
"Letzte als funktionierend bekannte Konfiguration"
Das hat an meinem Arbeitsplatz PC mit Windows 10 Ernteprise Lizenz nicht funktioniert.
Der hat nach einer halben Stunde Neustartschleife immer noch versucht neu zu starten.
Er wurde gegen Mittag händisch von der IT repariert. Mit direkten zugriff. Das System wurde vom USB Stick gestartet. Weiter habe ich das dann nicht verfolgt.
Hier werden 2 Dinge wild durcheinander geworfen. Der Fehler hat nichts mit irgendeiner Cloud zu tun!
Virenscanner oder wie in diesem Fall EDR/XDR bekommen Updates! Auch Clients ohne Internetverbindung.
Oder lässt hier jemand seine Server/Clients blank nur weil sie keine Internetverbindung haben? Was da wohl Verantwortungsloser wäre, keinen Schutz zu haben oder ne Cloud-Anbindung…
Crowdstrike ist nicht ohne Grund Marktführer. Die sind gut in dem was sie tun, aber das lassen die sich was kosten.
Insofern könnte das eine gute Nachricht sein, die mit dem Gedanken gespielt haben dort Kunde zu werden, aber es sich schlicht nicht leisten konnten. Deren Preise könnten nun deutlich fallen. 😁
und ms365 lässt du gewissenhaft unter den Tisch fallen…
Nein, da bin ich voll bei dir. Deswegen meinte ich ja, es werden 2 Themen in den Kommentaren durcheinander geworfen. ggf. wäre es tatsächlich besser gewesen da 2 Blog-Einträge draus zu machen.
Ich bin ein absoluter Gegner der MS-Cloud. Aber der Part war heute aus meiner Sicht nur eine Schlagzeile. Gespürt habe ich davon nichts und MS hatte es ja auch recht flott in den Griff bekommen.
Ich bin auch ein Gegner davon jedwege Cloud-Anwendung zu verteufeln. Es gibt sinnvolle Einsatzzwecke.
OnPrem hab ich das aber in der Hand und wenn ich meine IT ordentlich im Griff habe in unter 30min. wieder am laufen… also ist das schon nen Cloud Problem.
Wirklich? Ich würde ja sagen das ist sehr stark verkürzt.
Du hast nie ein Update für eine Software eingespielt und dann lief etwas nicht wie vorausgesehen? Ihr setzt vermutlich nur selbst geschriebene Software ohne Abhängigkeiten an andere Komponenten ein, deren Quellcode ihr in- & auswendig kennt? Ihr seid dann nie von der Expertise eines Drittanbieters abhängig?
Netzwerktechnik und Firewalls sind natürlich OpenSource?
Sorry für die harschen Worte, aber ich denke du verwechselt "nicht im Griff haben" mit "außerhalb meines Zugriffs". Ich kann diese Ohnmacht gut nachvollziehen, aber das ist kein Maßstab für die Bewertung.
In welcher vernünftigen IT-Infrastruktur rollt man Updates auf einmal an alle Nutzer aus?
Hier geht es nicht um Cloud allgemein sondern darum, dass man seine IT-Infrastruktur nicht kopflos der Willkürlichkeit mächtiger Drittland-Konzerne wie Microsoft überlassen sollte.
Denn es passieren eben auch Fehler, das ist menschlich.
Nur…
Wenn alle auf den gleichen Betreiber bauen steht im Fehlerfall plötzlich die ganze Welt.
Warum sollte ein vom Internet isoliertes System unbedingt Updates brauchen?
Irgendwelche USB Sticks sind vorher auf anderen Systemen gescannt worden.
Natürlich darf keine Maschine in diesem Netz ins Internet,Logo.
"Having to type a 48 digit number on 5K machines, my carpel tunnel will scream and my eyes will melt."
ich hatte aber einen Rechner mit der Adruino IDE und konnte mir ein paar "Bad USB sticks" brennen, so daß sich das getippe der Keys auf einen Tastendruck reduzieren ließ.
Wer einen Barcode Scanner hat,asci ausgibt, kann einfach dieses benutzen.
natürlich blöd wenn der Server das USB im BIOS deaktiviert hat oder generell, keine neuen Keyboards akzeptiert, was ja eigentlich empfohlen wird.
Aber viele KVM bieten auch programmierbare Tasten und einen USB Anschluss.
Da 5k mal 48 Digits eintippen ist nur als malerische Hinweis zu verstehen. das wird kein BOFH machen.
das USB Bad hilft natürlich nicht so Recht wenn es 5k verschiedene 48 digits sind.
für den Hardware orientierten Admin hilft dann, die 5k Codes als Barcode Font ausdrucken und mit dem 40 Euro china Handscanner im Tastatur Mode einlesen.
ich weiß jetzt nicht, welcher KVM ein solches Scripten zulässt und wie diese 5k Maschinen zu verstehen sind.
5k einzelne Bleche, oder virtuelle Maschinen.
jedenfalls eine Fleißaufgabe…
wie der neueste Bericht hier oben zeigt kann man die Eingabe des 48 Digit Codes einfach überspringen um das booten in den Saveboot (ohne jeden Treiber) zu erzwingen
Mit einem programmierbaren KVM oder Bad USD Stick kann man dann doch alle 5k Maschinen halb automatisch von dem bösen .sys befreien.
Microsoft: Einmal Profis…
Windows ist nun mal das beste und sicherste Betriebssys der Welt.
Das ein Ring 0 Treiber einen BSOD wirft kommt leider immer wieder vor,wenn auch nur noch selten. Es programmieren immer noch Menschen, und die dütfeb Fehlern machen, aber/daher:
Dass ein Treiber einen BSOD wirft deutet heute auf schlampige Programmierung hin (es wirklich keiner ein so großes Pagefille um mal den gesamten Kern zu dumpen und sich mit debug analyze den Crash Bereich anzuschauen? Klar, alle wollen nur schnell Lösungen, die (evtl. generellen) Ursache interessiert niemanden)
Man könnte den Vorfall auch zum Anlass nehmen um zu verstehen/erkennen wie erpressbar die EU bei Nutzung von Drittland-Cloud-Diensten ist,
wenn z.B. in USA ein neues Regime an die Macht kommt.
Mir fallen Möglichkeiten ein, wie…
– Lizenzserver abschalten
– Accounts sperren
– Daten (Geschäftsgeheimnisse) abgreifen
– per Zwangs-Update Spyware ausrollen
– etc.
Rein nach dem Motto:
"Ihr macht jetzt 'was ich will' oder ich mach Euch kaputt!"
Das gleiche Szenarion dieser Möglichkeiten könnte jederzeit eintreten, wenn z.B. in Deutschland ein neues Regime an die Macht kommt und/oder auch das bestehende Regime eines Tages aus irgendwelchen Gründen nicht mehr auf die transatlantischen Verbindungen setzen oder gar sich gegen solche stellen wollen würde…
Dein Kompass ist kaputt!
Die genannte Bedrohung richtet sich von West nach Ost.
Wenn sich bei uns der Wind dreht, machen wir uns nur selber kaputt (und als Kollateralschaden dann halt noch andere europäische Länder/die EU).
Das gruselige ist: die Wahrscheinlichkeiten addieren sich bei uns… :(
> …könnte jederzeit eintreten, wenn z.B. in Deutschland ein neues Regime an die Macht kommt …
Das ist nicht vergleichbar!
Das Bedürfnis seine IT selbst auszuschalten nennt man 'Selbstbestimmung'.
Die Entscheidung von Dritten dagegen ist 'Bevormundung' oder 'Erpressung'.
Da bin ich sowieso mal gespannt. Die EU will jetzt in Selbstüberschätzung großen Technologiekonzernen wie Apple kräftig ans Bein pinkeln ohne zu begreifen, daß Apple mit einem Tastendruck etwa die Hälfte der in EU herumgetragenen Handys zu wertlosen Ziegelsteinen machen könnte.
Die EU hat mehr Einwohner als die USA, solch einen Markt gibt kein gieriger Konzern einfach mal nebenbei auf.
Wer seinen Krempel in der EU verkaufen möchte wird sich an die EU-Gesetze halten müssen.
Dieses Prinzip sollte auch bei Software knallhart eingeführt und durchgesetzt werden.
Es geht also mehr darum wie lange es dauert bis die EU die notwendigen Vorgaben/Gesetze macht.
Dann werdet ihr sehen wie schnell es plötzlich geht, bis die Konzerne sich daran ausrichten.
Das geht sehr sehr schnell.
Im Zweifelsfall rechnen die Kaufleute mit spitzem Bleistift. In der aktuellen Diskussion war von "Gewinnabschöpfung" (auf welcher rechtlichen Basis die auch immer sein sollte) die Rede – wenn unterm Strich eine rote Zahl steht ist man erst mal nicht verpflichtet, weiterzuproduzieren – das hat sogar Habeck erkannt.
Andererseits kann es politische Einflußnahme geben.
Soweit mir bekannt ist, haben weder Microsoft noch Apple ihre Dienste in Rußland abgeschaltet. Ich vermute die Anweisung dazu kam direkt aus dem weißen Haus. Dort vermeidet man seit 2 Jahren alles, was die USA völkerrechtlich zu einer Kriegspartei machen könnte (selbst Waffen werden nur als Ringtausch mit Drittstaaten geliefert), eine solche Abschaltung dagegen könnte man schon als "kriegerischen Akt" verstehen.
Auch die Autodesk 3D Software – die werden viele nutzen – bezieht ihre Lizenz aus den USA im Abo-Zwang. Da ist dann auch schnell der Maschinenbau mal in der langen Kaffepause, auch wenn die Lizenzen x Tage ohne Klaud auskommen.
Schön die Bauern mussten Vor Jahrhunderten feststellen, das Monokulturen ordentlich Kohle bringen, aber wenn was ist, die komplette Ernte aufgefressen oder zerstört wird.
man hat daher die Flächen mit den Monokulturen begrenzt, breite Knicks angelegt, und nebenan, anderes gepflanzt.
Eine seit Jahrhunderten bewährte Technik.
Aber schon gut, jeder hat das Recht aus den eigenen Fehlern zu lernen…
in sofern:
Was soll schon passieren, wenn dieselbe Software benutzen?
Weil ist ja billiger, sagte der Controller und ging nach Hause, wegen des Blauen Bildschirm konnte er ja eh nicht mehr arbeiten.
Die Admins werden das schon richten.
ROFL – Popcorn-Maschine läuft heiß. Pharma, Waffen und IT – MonkeyBusiness.
On-Prem wäre und ist ihn diesem Fall ebenso betroffen. Zumindest was CrowdStrike betrifft.
Da hat man Kasperskys Sicherheitsprodukte verbannt, von wegen zu großes Risiko, und nun das… Ich denke, der Herr Kaspersky hat heute Abend Wangenschmerzen vom breiten Grinsen. Und wenn wir Glück haben, lacht Putin sich tot.
Es wird sich trotzdem nichts ändern. (Wieder hin zu on Prem)
Weil BWLer entscheiden was für die Firma gut ist.
Die IT Abteilung hat eigentlich nichts mehr zu sagen…
Jupp, ich erlebe gerade so eine Restrukturierung. Die Hoheit über IT-Entscheidungen wird von Zahlen- & Floskel-Schubsern gekapert. Wenn sich die Unternehmensführung sowas in den Kopf gesetzt hat, kann man nur zuschauen. Das ist einfach Realität. Da wir als ITler aktuell nicht auf einen bestimmten Arbeitgeber angewiesen sind, kann man das Wegfallen der eigenen Manpower in die Wagschale werfen, um etwas zu erzwingen. Aber am Ende wird das auch nicht ganz oben ankommen.
"Führung von unten" (?)
Die GL sagt:
"wir lassen uns nicht erpressen, wir doch nicht.
Jeder ist ersetzbar, und der Neue wird sogar billiger sein,weil er noch nicht weiß,was seine Arbeit wert ist. Reisende soll man ziehen lassen."
Sigh
vielleicht Solarwinds reloaded;-)?
Könnte doch sein, dass "Freunde" eben mal einen Treiber optimiert haben.
um sich großteils selber lahmzulegen oder wie? Was stimmt mit dir eigentlich nicht?
naja wäre nicht das erste mal das sich die Dientse selbst ein Bein stellen (ungeplannt versteht sich) ;-P Auch NSA Agents sind nur Menschen und keine Götter (auch wenn sie vregleichbare Macht haben)
Im Prinzip kann das mit jeder Virussignatur eines beliebigen Virenscanner.
Ich halte Virenscanner, vorausgesetzt man nutzt sichere Proxies, Mailfilter, Applocker und USB-Ports korrekt, heute für verzichtbar. Die finden frische Viren sowieso nicht. Für Wechseldatenträger mag es Sinn machen und für Vollständige Scans von Netzlaufwerken.
Problem: Alle schrieben einem den Virenscanner vor. Schlangenöl und die gefühlte Sicherheit.
Was ist älter als der Börsen Kurs von vor einer Stunde?
Die Virensignaturen die gerade heruntergeladen werden.
Sorry 4 OT
Fremde Firmen/Staaten können also ganz leicht in Deutschland kritische Infrastruktur lahmlegen. Wie kann man nur so blauäugig sein?
Es lassen sich auch ganz leicht die modernen Traktoren lahmlegen. Folge wäre dann eine große Hungersnot.
Em, Du meinst jetzt die gestohlenen Ukrainischen Trecker, die dank Geofencing in Russland nicht mehr funktionieren, so das keiner mehr Futter erzeugen kann?
War eine Anspielung darauf. Könnte man aber auch aus anderen Gründen als Krieg machen um eigene Interessen durchzusetzen.
Das ist SaaS aka Cloud und was JS-Kiddies als Cloud begreifen.
Ändern wird sich nichts wie nach dem ersten Terminator Film oder als gezeigt wurde das Tesla Mitarbeiter irgendwelche Teenies im Auto beim Beischlaf beobachten.
Dependencies und Privatsphäre.
Man sollte endlich mal laut darüber nachdenken, Firmen für den Software-Mist, den sie produzieren, haftbar zu machen. Nicht für jeden kleinen Fehler, aber für solche Klopse wie jetzt. Was allein Microsoft in letzter Zeit produziert hat, macht einen sprachlos. Oder die unglaublichen Sicherheitslöcher bei Cisco und Juniper. Die Kunden machen das Qualitätsmanagement, äh – Betatesten, haben den Ärger und die Kosten.
Auch wenn eine Bordkarte handgeschrieben ist (hatte ich auch schon, als die Bahn das Glasfaserkabel zum Frankfurter Flughafen angebohrt hat), sollte man sie trotzdem teilweise verpixelt anzeigen – zumindest den Buchungscode.
So konnte ich zumindest nachvollziehen, daß Herr Kothari das Ziel seines Fluges mit einer Stunde Verspätung trotzdem erreicht hat 😅
George Kurtz, CEO CrowdStrike, 21:54 CET:
The letter: https://www.crowdstrike.com/blog/our-statement-on-todays-outage/
Quelle: https://x.com/George_Kurtz/status/1814388276486136251
Vor sehr sehr vielen Jahren hat unsere Abteilung mal einem Kunden, einem Produktionsbetrieb, eine komplexe Steuerung verkauft. Ich war ziemlich konsterniert, dass der die zweimal haben wollte, mit einem großen Umschalter dazwischen. Seine Erklärung: Wenn Ihre tolle Steuerung mal ausfällt, schalten wir um auf die zweite und können weiter produzieren. Nun ja, zweimal verkauft ist besser als einmal.
Wie der Teufel es will – die tolle Steuerung fiel immer wieder aus. Der Kunde schaltet um, produziert weiter, meckert bei uns und wir müssen auf Gewährleistung reparieren, es wurde für uns teuer.
Was ich damit sagen will – Der Kunde hatte das Wort Redundanz verstanden und war bereit, dafür Geld auszugeben.
Was mir daher nicht einleuchtet: Auch bei Software muss es möglich sein, umzuschalten, d.h. quasi auf Knopfdruck die bisherige fehlerfreie Software wieder von zentraler Stelle aus auf allen Systemen aufzuspielen. Wenn man das nur vom Admin vor Ort machen lassen kann, ist das ein zweiter gravierender Fehler im System. Mit anderen Worten, da haben eine Menge Leute die Worte Redundanz und Betriebssicherheit nicht verstanden.
Soweit meine Ingenieur-Sicht, aus einer Zeit, als Software noch was neues war. Irgendwo in den Kommentaren habe ich den neumodischen Begriff "Shadow-Kopie" und "Automatisches Einspielen" gelesen, klingt für mich sehr ähnlich dem Umschalter, den wir damals auf Kundenwunsch einbauen mussten.
Natürlich geht das.
Microsoft hat dafür mehrere Verfahren entwickelt.
Last good known state.
das startet nach dem n-ten Fehlversuch, das Windows, das es zum letzten Mal bis zum Hochfahren aller Dienste gebracht hat.
Hilft zwar eher bei kaputter Registry, aber immerhin.
oder wie weiter oben startet man das ganze System generell von einer virtuellen Platte, von der man Schattenkopien, snapshots anlegt. Das kostet zwar minimal Performance, aber…
Auch hier kann man programmieren das im Falle eines Crashes die vorherige Schatten Kopie oder andere VM gebootet wird. Auch bei 5k Maschinen. Dank COW etc.
geht das sogar vollautomatisch, wenn man mag.
irgendwie verstehe ich nicht, warum offenbar zig tausende Windows Systeme ohne dieses Feature betrieben werden.
Es ist kostenlos in Windows Enterprise und IOT enthalten.
Hat da wer ne Erklärung?
Geht das nicht zusammen mit Bitlocker?
Em, Du meinst jetzt die gestohlenen Ukrainischen Trecker, die dank Geofencing in Russland nicht mehr funktionieren, so das keiner mehr Futter erzeugen kann?
Das halte ich für einen Pyrrhussieg.
Einerseits wird GPS in diesem Gebiet der Drohnen wegen ganz massiv gestört – da ist nichts mit "Geo"-Fencing, weil der Trecker im Zweifelsfall überhaupt nicht mehr weiß, wo er sich befindet.
Andererseits traue ich auch den Russen zu, die Motorsteuerung soweit umzubauen, daß sie nur noch auf Lenkrad, Gas und Kupplung gehorcht – und nicht mehr auf Satellitensignale.
Damit verliert man zwar die ganzen "Bells und whistles" wie quadratmetergenau optimierte Ausbringung von Saatgut und Dünger nach Bodenwertzahl oder den Autocruiser, der ganze Felder beliebiger Geometrie mit optimalen Spuren abmäandrieren kann, aber "verhungern" werden die Russen sicher nicht. Sind sie im zweiten Weltkrieg auch nicht.
Sorgen sollten sich eher deutsche Landwirte machen, die für einen solchen Trecker mit den passenden Lizenzen inzwischen gerne mal eine halbe Million hinblättern müssen, was mit ihrem Wunderwerk passiert, wenn die John-Deere-Cloud oder Klaas-Cloud mal ausfällt.
Natürlich geht das.
Microsoft hat dafür mehrere Verfahren entwickelt.
Last good known state.
das startet nach dem n-ten Fehlversuch, das Windows, das es zum letzten Mal bis zum Hochfahren aller Dienste gebracht hat.
Hilft zwar eher bei kaputter Registry, aber immerhin.
oder wie weiter oben startet man das ganze System generell von einer virtuellen Platte, von der man Schattenkopien, snapshots anlegt. Das kostet zwar minimal Performance, aber…
Auch hier kann man programmieren das im Falle eines Crashes die vorherige Schatten Kopie oder andere VM gebootet wird. Auch bei 5k Maschinen. Dank COW etc.
geht das sogar vollautomatisch, wenn man mag.
irgendwie verstehe ich nicht, warum offenbar zig tausende Windows Systeme ohne dieses Feature betrieben werden.
Es ist kostenlos in Windows Enterprise und IOT enthalten.
Hat da wer ne Erklärung?
Geht das nicht zusammen mit Bitlocker?
Wisst ihr, wie man innerhalb von wenigen Sekunden wieder ein voll funktionierendes System hat, selbst dann, wenn ein Update alles zerhauen hat?
Man benutzt das Dateisystem BTRFS oder ZFS und macht vor jedem Update einen Snapshot. Das dauert bei diesen Dateisystemen nur ca eine Sekunde und lässt sich auch automatisieren.
Nach dem fehlerhaften Update bootet man in den Bootloader GRUB und wählt dann den letzten Snapshot unmittelbar vor dem Update aus. Das dauert auch nur ca eine Sekunde und das Betriebssystem bootet wieder ganz normal, ohne dass man das fehlerhafte Update manuell löschen müsste.
Das ist einfach nicht mehr da.
Windows kann leider kein BTRFS und kein ZFS, also muss man für dieses Feature Linux einsetzen.
MAC hat sowas ähnliches mit "Timemachine".
Bei openSUSE heißt das Tool, das diese Snapshots erzeugt, "Snapper ".
Bei Linux Mint heißt das Tool "TimeShift".
Windows kann inzwischen auch Snap Shot nebst COW.
Der Default Installer macht einen Snapshot, wenn es erlaubt würde.Man kann dahin leicht zurücken.
Via BCDedit kann man das auch vollautomatisch machen, was man im embedded Bereich gerne hat, da oft head less
Ich weiß jetzt nicht wieso ich Windows verteidigen.
Es müsste der System integrattor nur machen und nicht die Defaults übernehmen.
Aber das muß Cheffe natürlich zahlen.
Und mit 12 Jahre alten fährt es sich doch auch gut und man spart sogar Sprit, weil die dank der Hätte so einen geringen Rollwiderstand haben.
Die Dateien C-00000291*.sys enthalten nur Nullen.
Da diese Updates in komprimierter Form verteilt werden, hätte das ungewöhnliche Update auch anhand der zu kleinen Dateigröße auffallen können, denn diese Nullen werden extrem stark komprimiert, weil man neben dem Wert Null nur noch deren Anzahl braucht.
Da fehlt ein Plausbilitätstest auf die Dateigröße bzw deren Abweichung von der sonstigen normalen Dateigröße.
Diese Datei kann eigentlich auch kein Treiber sein, da ein Compiler oder Linker keine Datei schreibt, die nur aus Nullen besteht.
Im BSOD steht als Verursacher auch ein anderer Dateiname drin, nämlich "csagent.sys".
Wenn die Datei im Dateiheader keine Kennung für ausführbare dll hat ("MZ" ganz vorne in der Datei), warum versucht Windows dann, diese Datei trotzdem auszuführen?
Wenn diese Datei nur die Signaturdatenbank ist, warum ist der Treiber "csagent.sys" dann nicht robust genug, um deren falsche bzw völlig fehlende Struktur zu erkennen?
X oder TOR-Relays scheinen auch betroffen gewesen zu sein, denn ich wurde dort ausgeloggt und die TOR-NoScript-Erweiterung meldete ein "possible security breach".
Die ersten Login-Versuche schlugen fehl, weil er nach der Passworteingabe noch einen Code wollte, den er an meine eMail-Adresse geschickt hat, aber so ein Code kam gar nicht an.
Nach drittem TOR-Neustart und nochmaligem Loginversuch bei X reichte dann die Eingabe der im X-Profil gespeicherten emailadresse, ohne einen dorthin geschickten Code aus, um sich erfolgreich einzuloggen.
Sollte man Tor Relays, die nach Deiner Beschreibung offenbar Crowdstrike verwenden, überhaupt nutzen?
Hi…
Sorry, aber war wohl (leider) noch nicht annähernd genug "heftig" – leider muß das anscheinend für die dumme Spezies "Homo Sapiens" erst so eminente Kollateralschäden in Zahl von mehreren Menschenleben nach sich ziehen, bevor's da ein klein wenig Abrücken von der Monetarisierungsgier gibt.
Ansonsten zählt immer NUR "Gewinne, Gewinne, Gewinne"…und morgen spricht eh keiner mehr davon, weil's 'ne andere viel interessantere Meldung gibt. 🤷♂️
Wir haben's echt nicht verdient zu überleben, weil wir absolut nur Destruktiv agieren! ☠️
Analyse, wodurch der BSOD ausgelöst wird:
x[.]com/Perpetualmaniac/status/1814376668095754753
Der Treiber csagent.sys versucht von Speicheradresse 0x9c zu lesen.
Das ist bei Windows ein verbotener Bereich und der Kernel schmeißt den Treiber sofort raus.
Der Treiber wollte eigentlich aus der (fehlerhaften *291*.sys) Datei die Grundadresse oder Startadresse lesen, dann 0x9c zu dieser Adresse addieren und von der resultierenden Adresse seine Werte holen (also praktisch einen Dateiheader überspringen).
Da die fehlerhafte Datei aber nur aus Nullen bestand, war die falsche Startadresse auch Null und damit auch die resultierende Adresse falsch.
Der Programmierer des Treibers hat nicht geprüft, ob die Startadresse Null ist, der Pointer also ungültig ist und auf gar kein gültiges Objekt zeigt.
Es ist also ein Pointer–Fehler im Treiber, der bisher aber nicht auffiel, weil die älteren Signaturdateien korrekte Startadressen lieferten.
Die neue Signaturdatei lieferte aber eine falsche Startadresse Null, deshalb zeigte der berechnete Pointer auf ein ungültiges Objekt und der Windows-Kernel schmiss den Treiber aus.
Der C++ Programmierer muss einen Pointer auf Null prüfen und falls es Null ist, dann darf er ihn nicht benutzen, weil der Pointer ungültig ist und auf irgend ein zufälliges Objekt zeigt. Wenn dieses Objekt in einem RAM-Bereich liegt, der nicht zum Programm gehört, dann merkt der Kernel das und beendet den Frevel.
Wenn man zum Beispiel einen Dateinamen lesen will und man legt einen Pointer auf den Anfang dieses Strings, das Ergebnis ist aber NULL, dann bedeutet das, der String und damit der Name ist gar nicht vorhanden, der Pointer also ungültig.
Dann darf man da nicht einfach weiter lesen und so tun, als ob er doch vorhanden und gültig wäre, sondern man sollte eine Fehlermeldung anzeigen "Lesefehler".
Also gleich mehrere Fehler auf einmal:
– Fehlende Pointer-Überprüfung (kein Null-Check)
– falsche Signaturdatei (lauter Nullen), damit falsche Startadresse und falsche berechnete Leseadresse.
– die zu geringe Dateigröße der komprimierten Null-Signatur-Datei ist nicht aufgefallen.
– Das Update wurde gleichzeitig überallhin verteilt, anstatt eine Verzögerung einzubauen, damit man im Fehlerfall eine Weiterverbreitung verhindern kann.
Hervorragend erläutert, danke.
Lt twitter gab es auch Dateien mit anderem Inhalt als null Bytes, die auch BSOD verursacht haben.
Takeaways:
Kein Sanitation, kein Testing einfach Push und Deploy? Nicht staged, nein komplett für alle, weltweit? Ware reift beim Kunden. Keine Sau hat sich di e Mühe gemacht, das Resultat auf einem Rechner anzuschauen.
Programmierfehler passieren, das ist für mich nichts Schlimmes. Mich erstaunen immer solche tiefen Einblicke in die Art und Weise, wie große Tech-Unternehmen operieren. So welchen vertraut man doch gerne die eigene IT Infrastruktur an…
Na klar, weil die wissen wie man professionell shreddert.
Bei CrowdStrike war es ein BLUTIGER Anfängerfehler!
Software-Frickler bzw. -Hersteller^WVerbrecher, die noch immer "SEI CERT C++ Coding Standard"
https://wiki.sei.cmu.edu/confluence/display/cplusplus, "Common Weakness Enumeration" https://cwe.mitre.org/ oder OWASP ignorieren, handeln GROB fahrlässig!
Ein direkter Link zum SEI CERT C Coding Standard (2016 Edition) als PDF…
Nur zur Ergänzung für Mitleser – ich habe am Artikelende in einem Link auf einen Folgebeitrag mit einer Analyse verwiesen, warum es zum fatalen Fehler kam. Dort werden der Kommentar von Bolko und weitere Informationen zusammen gefasst.
em…die Startadresse ist ja nicht Null, sondern 9c.
darum ist diese Abfrage if NULL nicht zielführend.
Es wird das Datensegment mit Null geladen, das ist natürlich fatal.
Es wurde schon vorher gegen eine Grundregel sicheren Programmierens verstoßen:
Traue keinen externen Daten. Prüfe bei jedem Wert von außen die Grenzen. Der Code sieht dann zwar nicht so schön wie im Lehrbuch aus, man hat dann erstmal 30 Zeilen Parameter Check ehe 3 Zeilen Programm kommen…und das Problem, was machen, wenn der Parameter nicht in den Grenzen ff. liegt?
Das kostet natürlich eine irre Zeit, und zu 99,9999% sind die Werte OK oder unbemerkt falsch.
Tavis Ormandy sieht das anders https://x.com/taviso/status/1814762302337654829
Ich hab mich vor lachen fast nass gemacht, als plötzlich das große Gejammer losging.
Blödheit wird zum Glück doch manchmal noch bestraft – nur leider trifft es auch wieder viele Unschuldige.
Den ganzen Cloud-Jüngern kann ich nur wünschen, dass es bei manchen als Impuls genügt hat, um ihr Gehirn wieder einzuschalten.
Die Unbelehrbaren sollen bei ihrem Ritt auf der Cloud ruhig für immer im Nirvana verschwinden – das währe sicher nicht nur zu meiner Belustigung
Unschuldig ist nur wer mitdenkt und sich wehrt.
Cloud-Jünger schalten ihr Gehirn nicht einmal dann ein, wenn der Vorschlag-Hammer anrückt.
Alles stumpfe Leute, die kein Mittleid verdienen.
Ihr habt ja anscheinend eine E-Mail Adresse (oder habt ihr zum Kommentieren eine Fakeadresse angegeben?) – also seid ihr, wenn auch vielleicht nicht Jünger, ebenfalls Cloud-Nutzer. Aber andere Abwerten fühlt sich immer gut an, ne?
Zu "Ihr habt ja anscheinend eine E-Mail Adresse (oder habt ihr zum Kommentieren eine Fakeadresse angegeben?)": Kommentieren hier im Blog ist ohne E-Mail-Adresse möglich, und Alzheimer hat in der Tat keine E-Mail-Adresse angegeben. Nur als Anmerkung.
Laut Microsoft-Blog waren 8,5 Millionen Windows-Computer von dem Crowdstrike-Fehler betroffen:
"We currently estimate that CrowdStrike's update affected 8.5 million Windows devices"
blogs[.]microsoft[.]com/blog/2024/07/20/helping-our-customers-through-the-crowdstrike-outage/
Elon Musk hat CrowdStrike von allen Computern seiner Unternehmen entfernt:
"We just deleted Crowdstrike from all our systems, so no rollouts at all"
x[.]com/elonmusk/status/1814336158505050523
habe es gestern gesehen, wollte aber WE machen, Einordnung kommt in einer Nachlese.
Geschätzter Schaden durch NotPetya (Lieferkettenangriff per Auto-Update eines ukrainischen Staats"trojaners"): 10 Mülliarden US-$ https://en.wikipedia.org/wiki/Petya_(malware_family)#Impact
Geschätzter Schaden durch CrowdStrike Falcon: 24 Mülliarden US-$
https://en.wikipedia.org/wiki/2024_CrowdStrike_incident#Cost
Wohl bekomm's!
Seit gestern 20.7. gibt es ein neues "Microsoft Recovery-Tool" ( Powershell-Script MsftRecoveryToolForCS.ps1 )mit Anleitung:
techcommunity[.]microsoft[.]com/t5/intune-customer-success/new-recovery-tool-to-help-with-crowdstrike-issue-impacting/ba-p/4196959
Anleitungen zur Fehlerbehebung von Microsoft für Windows 10 und Windows 11s:
support[.]microsoft[.]com/de-de/topic/kb5042421-crowdstrike-issue-impacting-windows-endpoints-causing-an-0x50-or-0x7e-error-message-on-a-blue-screen-b1c700e0-7317-4e95-aeee-5d67dd35b92f
Fahrlässige Sachbeschädigung und Schadensersatz?
Ist für solche "Taten" ja wohl nicht anwendbar, oder?
Sonst wäre Microsoft und all die anderen Pfuscher ja auch längst pleite
Ich bin auch der Meinung, dass Kritische Systeme wie Kliniken oder Verkehrssysteme ihre IT überdenken sollten. Was uns dies aber auch sagen sollte, von dem niemand spricht: wir sollten die IT nicht nur überdenken, sondern uns allgemein weniger abhängig davon machen. Es gibt nicht nur Updates und Cyberangriffe, sondern auch Stromknappheit, Sonnenstürme und was weiss ich. Auch wenn bald alles vom Kühlschrank bis zum OP Saal mit KI und Cloudlösung automatisch läuft, brauchen wir ein analoges, stromfreies, durch uns Menschen umsetzbares Fallback. Haben wir das?