
") [English]Am 20. Februar 2025 kam es zu einer größeren Störung der Microsoft Azure Cloud in Norwegen. Die betreffenden Dienste waren über Stunden nicht erreichbar. Unter den heftig Betroffenen waren auch Norwegens Behörden sowie die Regierung, da diese ihre Dienste in die Microsoft Cloud verlagert haben.
[English]Am 20. Februar 2025 kam es zu einer größeren Störung der Microsoft Azure Cloud in Norwegen. Die betreffenden Dienste waren über Stunden nicht erreichbar. Unter den heftig Betroffenen waren auch Norwegens Behörden sowie die Regierung, da diese ihre Dienste in die Microsoft Cloud verlagert haben.
Azure-Ausfall in Norwegen-Ost
Zum 20. Februar 2025 kam es zu einer Störung der Microsoft Azure-Cloud in der Region Norwegen-Ost, wie man aus nachfolgendem Post entnehmen kann.
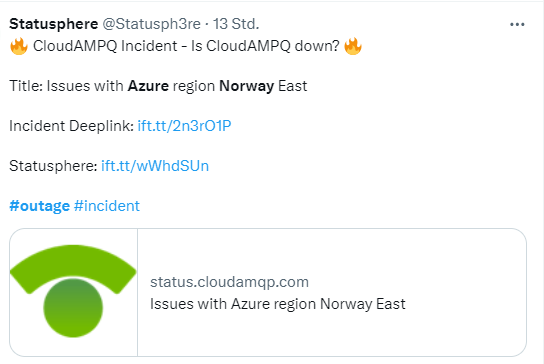
Am 20. Februar hieß es gegen 10:23 UTC, dass es bei Azure-Servern in Norwegen-Ost zu Verbindungsproblemen kommen kann. Gegen 10:53 UTC hieß es, dass man die Störung untersuche – und gegen 14:17 UTC wurde mitgeteilt, dass die Azure-Dienste wieder verfügbar seien.
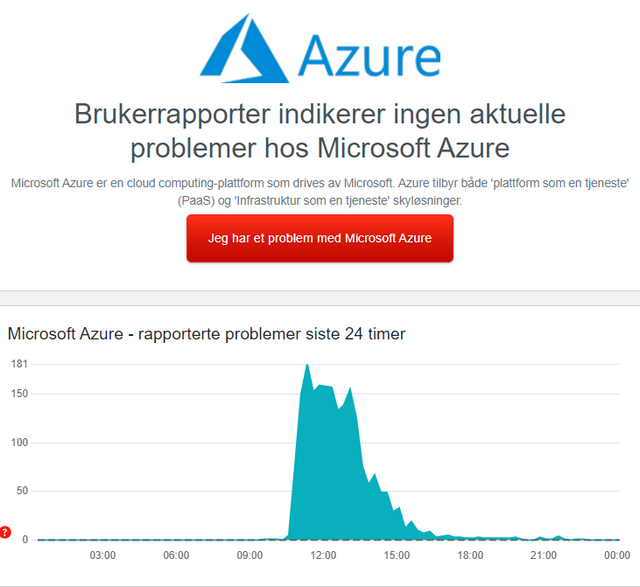
Auf Downdetector lässt sich erkennen, dass die Störung am Vormittag begann und bis zum Nachmittag des 20. Februar 2025 anhielt – obwohl das Störungsaufkommen nicht wirklich hoch war.
Böse Folgen für Unternehmen und Behörden
Bereits gegen 18:00 Uhr des gleichen Tages gab es im Windows-Forum einen Eintrag, der sich mit dem Ausfall und den sich daraus ergebenden Erkenntnisse befasste.
Am Morgen des 20. Februar 2025 sei zu einem Azure-Ausfall gekommen, wobei die Probleme erstmals gegen 9:00 Uhr Ortszeit auftraten und mehr als drei Stunden anhielten. Das Microsofts Azure Service Health Dashboard zeigte trotz anhaltender Probleme für den Azure-Bereich Norwegen einen "grünen" (voll funktionsfähigen) Status.
The Register hat den Vorfall in diesem Beitrag aufgegriffen, denn durch den Azure-Ausfall kam es bei norwegischen Unternehmen und Behörden zu schweren Störungen der digitalen Infrastruktur. Mehrere Regierungswebsites, die Online-Dienste für Bürger bereitstellen, waren durch den Azure-Ausfall lahm gelegt. Die Website der norwegischen Regierung, Regjeringen.no, war für einige Stunden außer Betrieb.
Für die Region Norwegen-Ost war Cosmos DB ausgefallen und nicht verfügbar. Azure Cosmos DB ist ein von Microsoft angebotener, weltweit verteilter Datenbankdienst, der darauf ausgelegt ist, modernen Anwendungen Hochverfügbarkeit, Skalierbarkeit und Zugriff auf Daten mit geringer Latenz zu bieten, heißt es in der Wikipedia.
Durch den Azure-Ausfall waren bei einigen Nutzern Webanwendungen nicht verfügbar, Speicherkonten (OneDrive) funktionierten nicht, und Azure Virtual Desktop war ebenfalls ausgefallen. Allerdings waren wohl nicht alle Azure-Kunden in Norwegen betroffen.
Aber die Ausfälle der Regierungsdienste und -webseiten verursachten, in Kombination mit der Diskrepanz, dass der Azure-Status alles im grünen Bereich signalisierte, den Zorn der betroffenen Benutzer. Im Windows-Forum ist der Ausfall nett aufbereitet; dort heißt es, dass Cloud Computing zwar einen beispiellosen Komfort und Skalierbarkeit bietet. Der Netzausfall in Norwegen zeige jedoch, dass die Abhängigkeit von zentralisierten Cloud-Plattformen – selbst von Branchenführern wie Microsoft – erhebliche Schwachstellen aufweist.
Der Fluch der Cloud
Der Vorfall sei sowohl für Cloud-Anbieter als auch für die Kunden ein Weckruf hinsichtlich der Notwendigkeit robuster Failover-Mechanismen und Redundanz. Selbst wenn ein Dienst wie Azure hohe Gesamtverfügbarkeitszeiten erreicht, können lokale Ausfälle schwerwiegende Folgen haben.
Kritisiert werden auch die irreführende Indikatoren, die insbesondere bei unternehmenskritischen Vorgängen im öffentlichen Sektor zu verzögerten Reaktionen und längeren Ausfallzeiten führen können. In einem Regierungsumfeld, in dem Vertrauen und Zugänglichkeit von größter Bedeutung sind, können solche Ausfälle das Vertrauen untergraben.
Wenn Bürger keinen Zugriff auf öffentliche Dokumente oder Informationen über ihre Führung haben, werde das Vertrauen der Bürger in die Digitalisierung durch den Staat stark geschwächt. Der Beitrag im Windows-Forum geht noch in allgemeiner Form auf die Folgen des Ausfalls von Cloud-Funktionen ein und zeigt, welche Risiken dort lauern – denn es gab in der Vergangenheit ähnliche Fälle. Sieht so aus, als ob einigen Leuten langsam bewusst wird, dass "Cloud nur Rechner von anderen Leuten sind", die nicht immer funktionieren müssen.









Seit 2019 gibt es für "Norway East" drei Availability Zones (kurz: AZ; dt. Verfügbarkeitszonen). Damit ist eine zonenredundante Konfiguration möglich. Es ist auch für Cosmos DB verfügbar.
Eine AZ kann mehrere Data Centers (kurz: DC; dt. Rechenzentren) umfassen. Bei einer Aktivierung der Zonenredundanz greift das Failover, indem eine AZ die ausgefallene AZ übernimmt. Die DCs sind physisch voneinander isoliert, aber miteinander verbunden.
Entweder habe ich es überlesen oder die zonenredundante Konfiguration wurde in der Konstellation nicht genutzt. Oder noch schlimmer: Hebeln Cosmos DB und weitere Azure-Dienste die zonenredundante Konfiguration mit einem Failover innerhalb einer Azure-Region schon im Fundament aus, sobald eine technische Störung auftritt?
Mir persönlich fehlt in diesem Vorfall die technische Transparenz, was genau zur Störung geführt hat und welche Auswirkungen es auf eine Azure-Region hat.
Link zum Thema "Availability Zones"
https://learn.microsoft.com/de-de/azure/reliability/availability-zones-overview?tabs=azure-cli
Link zum Thema "Azure-Dienste mit Unterstützung für Zonenredundanz"
https://learn.microsoft.com/de-de/azure/reliability/availability-zones-service-support
Da Microsoft m.W. keinen Post Incident Report veröffentlicht hat, bleiben deine Fragen offen. Die Botschaft des Artikels ist aber schlicht: Die Benutzer, die etwas mit Unternehmen oder Behörden in den betroffenen Zonen in der fraglichen Zeit erledigen wollten, waren gekniffen. Microsoft zeigte "alles gut" im Azure Status-Dashhboard an – ergo würden Admins dann eher eine andere Ursache ausmachen.
Und erzähle mir nicht, dass in Norwegen alle IT-Entscheider nichts von der Möglichkeit einen zonenredundanten Konfiguration wissen oder meinen, das nicht zu brauchen. Aus dieser Sichtweise hat der Artikel genügend Relevanz, auch ohne die Antworten auf deine Fragen veröffentlicht zu werden. Denn nun könnten auch IT-Entscheider in Schland nachrecherchieren, weshalb, warum es da im Norden geknallt hat.
Ich bin ganz auf deiner Seite, alles gut. Parallel bin ich im Risikomanagement tätig. Daher wäre es für mich interessant gewesen, wie die Details aussehen, um noch mehr Argumente für einen anderen Weg bzw. für das Notfallhandbuch zu haben.
Was soll's Reden alleine nützt eben nichts bzw. bringt die Verantwortlichen nicht zum Nachdenken. Also geht es eben den Weg, das man aus Schaden klug werden bzw. dazu lernen muss. Mal sehen, was die Konsequenzen daraus sein werden.
Man wird das Gefühl nicht los, dass Microsoft solche Ausfälle absichtlich herbeiführt. So oft wie der ganze Quark ausfällt, so bescheuert können die doch nicht sein?! Jetzt, wo so viele Firmen, Behörden, etc. davon abhängig sind, kann man ja bisschen gängeln. Einfach nur noch gruselig…
Naja, Microsoft zeigt immer mehr, dass seine eine Hand nicht weiss was die anderen Hände machen. Dies zeigt zum Beispiel auch das jüngste DKIM Thema. Vielleicht nur ein Kommunikationsproblem im Frontend Problemcheck? Man weiss es nicht. Jedenfalls hat es riesen Auswirkungen weil alle panisch ihre DNS Einträge anpassen. Wenn diese Arbeitsweise auch auf "Windows Updates" und "Cloud Engineering" zutreffen – wovon ausgegangen werden darf – kann man sich ausmalen wohin dies künftig noch führen wird :) Aber solange keine Haftbarkeit für wirtschaftliche Schäden hergestellt wird, sind die Schmerzen bei Microsoft viel zu gering.
*** GB: Kommentar gelöscht, da wenig zielführend – bitte um Zurückhaltung – danke ***
Immer das gleiche Drama,
zeigt mal wieder, dass an den falschen Stellen, die falschen Entscheidungen getroffen wurden, sorry, aber wer Systeme in die Cloud legt, sollte sich einfach mal EINE Frage stellen:
Kann man damit leben das dieses System evtl. mal Stunden oder gar Tage NICHT verfügbar ist?
Sollte die Antwort NEIN sein, dann solltest das System auch nicht in die Cloud gebracht werden.
Wann fangen die Entscheider mal über das Thema Abhängigkeit nachzudenken an, müssen wohl erst noch mehr Ausfälle für Störungen sorgen…
Dann frage ich dich, was ist die Alternative? Fehler und Ausfälle können immer und überall passieren, in jedem Rechenzentrum, egal ob da nun Microsoft, Google, Amazon, Hetzner oder sonst wer vorne dran steht. Niemand ist frei von Fehlern. Man kann das Risiko minimieren, indem man sich anschaut welche Anbieter wie oft Ausfälle haben und da ist ganz klar erkennbar, das Microsoft da schon negativ hervorsticht. Dann kommt die nächste Überlegung, wenn der Dienst wirklich so kritisch ist, dass dieser am besten nie ausfällt, dann baut man den Dienst redundant auf und nutzt mehrere Anbieter. So eine Störung und Ausfall ist immer ärgerlich, muss aber auch immer in Relation gesehen werden zu der Wichtigkeit des Diensts. Ich behaupte einfach mal, wenn der Internetauftritt einer Behörde mal nicht erreichbar ist, ist das sicher ärgerlich und auch schlechte Presse, aber ein enormer Schaden entsteht da auch nicht.
Na du gibst die Antwort doch schon selber,
abhängig von Kritikalität, muss ein passendes Konzept dahinter stehen.
Ja, Microsoft sticht mehr als nur hervor, die stehen bei mir auf Platz 1, und klar, wenn deine Kritikalität es erfordert, dann brauchst halt 2-3 Anbieter.
Dein Beispiel mit der Website einer Behörde ist passend dafür, Kritikalität eben, was machst du wenn es nicht der einfache Internetauftritt ist, sondern z.b. Bund ID, ePA, what ever…. genau, Kritikalität ist eine Andere, ergo brauchst dafür ein anderes Konzept.
Was schief gelaufen ist, zeigt doch mal wieder, das sich scheinbar entweder niemand tiefgreifend mit den Abhängigkeitsketten beschäftigt hat, oder das Risiko als ZU GERING eingestuft wurde. (denn auch Amazon bietet, wie schon oben erwähnt Zonenredundanz und co)
Je kleiner und lokaler deine IT-Landschaft ist, desto einfacher lässt sich Ausfallsicherheit herstellen, was zum Umkehrschluss führt… je größer und globaler deine IT-Landschaft ist, desto komplexer wird es.
Realisierbar ist beides, Aufwand unterscheidet sich erheblich, maßgeblich ist halt die Kritikalität für den jeweiligen Dienst/Service/what ever.
Den gesunden Mittelweg zu finden, dürfte die große Challenge sein.
Von den ganzen neuen gesetzlichen Anforderungen im EU Raum mal ganz abgesehen, denn die schreiben dir ebenfalls an vielen Stellen, viel mehr nachdenken über die Abhängigkeitsketten, vor.
btw: Hast du schon ein Notfallplan in der Schublade?,
falls das EU-US Data Privacy Framework ins wanken gerät?
Alternative sind die eigenen Daten und Systeme lokal, unabhängig von irgendeiner Internet Anbindung, einfach und simpel.
Das geht oftmals garnicht mehr. Wenn du ein neues Bürogebäude mietest, haben die oftmals schon keine Räume mehr, die sich sinnvoll als Serverräume nutzen lassen. (Strom- und Kühlungsbedarf, gesicherter Zugang, …) Wir ziehen (vorraussichtlich) nächstes Jahr in ein neues Gebäude um, es wird gerade gebaut. Wir als IT wurden bei der Raumplanung garnicht gefragt und es hieß lapidar, es gibt zwei fette Netzanbindungem über 2 verschiedene Provider, wir mieten für eure Server Racks im Bullet-Proof-RZ in Frankfurt, macht mal. Immerhin nicht zu Ionos, hetzner, Azure, AWS oder Google verlagert…
und genau da muss es eben mal richtig knallen… dann kannst du auch sagen tja hätte ihr mal gemacht ;-P
Sowas ändert sich nur bei maximalen Schaden, sprich fette Kohle die verloren geht!
Man warnt und schlägt die pasende richtige Lösung vor und zwar schwarz auf weiss, das man auch was in der Hand hat und dann lässt man sie halt murksen… lernen durch Schmerz. Funktioniert!
Dann ist die Firma selbst schuld. Und in der IT werden Schuldige gesucht werden und Köpfe rollen, wenn dann was passiert, weil sich von dort niemand beschwert hat wegen der fehlenden Raumplanung usw.
| … Man kann das Risiko minimieren …
Wie kann man ernsthaft von Risiko*minimierung* reden, und gleichzeitig das Verlagern von Prozessen und Daten auf fremde Rechner empfehlen, wenn man anschließend weder Kontrolle über den fremden Rechner hat noch die komplexe Netzinfrakstruktur kontrollieren kann, die zum Zugriff auf die dorthin verlagerten Prozesse und Daten notwendig ist?
Zu den Fehlerquellen, die man selber unter Kontrolle hat, gesellen sich noch eine ganze Menge anderer Störquellen, die man dann eben nicht unter Kontrolle hat. Das ist in meinen Augen alles andere als eine Risikominimierung. Die vielen Ausfälle und Störungen diverser Dienste in den letzten Monaten beweisen doch wohl eher das genaue Gegenteil.
Irgendwie kommt es mir so vor, als wäre mit Risikominimierung seitens einiger Admins die Minimierung des persönlichen Risikos gemeint: für Dinge, die nicht unter der eigenen Obhut sind, kann man in diversen Fehlerfällen schlecht oder sogar garnicht verantwortlich gemacht werden.
Deine eigenen Rechner sind auch nicht unfehlbar, aber das vergessen leider viele Leute immer gerne. An vielen Lokationen bekommt man eben schlichtweg auch nicht die Gegebenheiten gestellt, die für ein zertifizierbares Rechenzentrum notwendig sind (redundante Stromversorgung, redundante Netzwerkanbindung, Zutrittskontrolle, BMA/EMA, Videoüberwachung, etc. pp.). Das sind alles Aufwände und Kosten die bei einem Cloud Anbieter eben nicht anfallen bzw. diese in der in der Verantwortung des Anbieters liegen und man diese im besten Fall vertraglich zugesichert bekommt. Ich sage ja auch nicht nimm den Cloud Anbieter, man kann ja durchaus auch ein Mittelweg gehen und ein Housing bei einem professionellen Anbieter für Rechenzentrumsflächen nutzen. Aber auch das alles muss in die Risikobewertung einfließen und wenn Du zu dem Ergebnis bzw. der Entscheidung kommst, dass dein Use Case so eine Kritikalität besitzt, dass dieser auf gar keinen Fall ausfallen darf und du das Risiko auf ein Minimum reduzieren willst bzw. alles unter deiner Kontrolle haben möchtest (heißt noch lange nicht, dass das Risiko minimiert wird), dann musst du das alles auch selber machen.
Und wenn der Cloud Anbieter einfach nichts mehr liefert, dann kann man die "vertragliche Zusicherung" die nächsten paar Jahre teuer einklagen und die Firma geht ohne Daten währenddessen pleite. Das übersehen die meisten Cloud Gäubigen und haben eben kein eigenes Rechenzentrum mit eigenem Fallback oder dezidierte Rechenzentrumsflächen mit Fallback dort mehr.
Nächste mal ist es eine Ransomware die lokale System aushebelt, da kennt sich DE recht gut aus. Bashing auf lokale Infrastruktur ist auch möglich! Ich will MS nicht in Schutz nehmen, denn für mich steht und fällt es nicht mit der Technik, sondern mit den Menschen die es einführen und konfigurieren bzw. warten und betreuen.
In dem Fall würde ich primär menschliches Versagen diagnostizieren, denn es schnell möglich den Fehler mit MS zusammen zu lokalisieren. Es gibt nicht umsonst die Möglichkeit direkt mit einem Escalation Manager in Kontakt zu gehen und ein kritisches Ticket erstellen. Da wird dann aber auch gefordert das du selbst 24h erreichbar bist und die Response Zeit von einem selbst "zeitnah" erfolgen musst.
Aber was da genau passiert ist, werden wir nie erfahren. Denke nicht das es eine 100% Transparenz geben wird sowohl vom Anbieter wie auch vom Nutzer selbst.
Ob meine Laufwerke oder Datenbanken lokal laufen oder in der Cloud interessierst doch die Ransomware nicht, es wird alles verschlüsselt auf das man Zugriff hat. Die Cloud ist kein zusätzlicher Sicherheitsmechanismus.
naja es ist aber schon ein Unterschied ob ich selbst verschuldeten Schaden habe oder dieser einfach hingenommen werden muss weil man es eben nicht mehr selbst in der Hand hat… du kannst auch Onprem mit Redundanz arbeiten…
Aberr IT sieht für mich in großen Firmen echt nach Vogel Strauß Taktik aus…
Kopf in den Sand und hoffen das nix schlimmes passiert.
Die Cloud ist ein Irrweg.
Durch die Abhängigkeiten sind ganze Länder und Regierungen erpressbar geworden.
[ironie]OnPrem ist nicht erpressbar? Ja dann :)[/ironie]
Whataboutism, kennste.
Auf Sendung mit der Maus Niveau erklärt: Hast Du keine Cloud-Abhängigkeiten, kann Dir keiner diese Cloud-Abhängigkeiten abschalten.
Jepp.
Cloud kann eine Ergänzung sein, aber man kann sich nicht darauf verlassen.
Ich weiß von einem KRITIS-Unternehmen, das vor einigen Jahren sehr stolz auf seine Azure-Hybrid-Cloud für seine Verwaltungssysteme war. Die haben zwar weiterhin eine Hybrid-Cloud, aber nicht mehr mit MS, stattdessen mehrere deutsche Provider. Hyper-V haben sie auch nicht mehr.
Der letzte Failover-Test mit Azure ist nämlich komplett daneben gegangen, und aus dem Test ist ein Ernstfall geworden. Die betreuenden Microsoft-Techniker waren auch komplett überfordert.
Am Ende hieß es von Microsoft lapidar "assumed customer error".
Seit dem arbeitet das Unternehmen hart daran, MS komplett zu verbannen.
Ich hoffe, aber glaube erst einmal nicht daran, dass die in Norwegen ebenso radikal vorgehen.
Hyper-V läuft super. Hier mehr als 50 Hosts damit.
naja wenn du OnPrem erpressbar bist, hast du was falsch gemacht.
Ich habe zu wenig Ahnung davon, aber wäre es möglich, dass auch ein OnPrem-Setup durch irgendwelche "Updates" lahmgelegt wird (sofern es am Internet hängt)?
hoheitliche Daten in der US Cloud. Superclever.
Was wenn die US Administration der Meinung ist, die Europäer hätten ein Problem mit Meinungsfreiheit und jetzt ziehen wir mal den Stecker?
Eigentlich ist es dann doch super, wenn Spiegel & Co in M365 sind, dann kann die NSA barrierefrei ermitteln, was es wirklich mit diesem Vorwurf auf sich hat.
Von daher: weiter migrieren, finde ich gut!
Hoheitliche und Unmengen anderer Daten schaffen auch unsere Behörden und Unternehmen in die Cloud, nicht besser als Norwegen.
Wenn ich allein an ein magentafarbenes Unternehmen (nicht das Frankfurter Magenta Druckhaus) denke: M365/Azure, Google, Huawei-OTC, …
Ich frage mich dann eher, welche mit mir in Kontakt stehende Organisation meine Daten nicht in eine "DSGVO-konforme" dem Cloud-Act unterliegende Cloud sendet.
Von daher: migrieren find ich sch…/nicht gut!
Ob es nun Absicht oder eine Störung war, weiß ich nicht, aber es ist ein guter Vorgeschmack, was passieren könnte, wenn der "Imperator Americanus"*) es anordnet.
*) *https://www.zdf.de/nachrichten/politik/ausland/usa-altes-rom-tech-milliardaere-zuckerberg-musk-trump-100.html
Ja, das wird für viele ein hartes Erwachen, wenn die tolle Cloud eines Morgens einfach nicht mehr da ist.