
 [English]Momentan kämpft Microsoft wohl mit einem Schluckauf seiner Cloud-Dienste. Ein Leser informierte mich bereits gegen 14:29 Uhr, dass Microsoft Entra seit 2 Stunden nicht mehr erreichbar sei. Da ich einige Tage unterwegs war, konnte ich nicht reagieren. Daher die Informationen, was inzwischen bekannt ist, kurz nachgereicht.
[English]Momentan kämpft Microsoft wohl mit einem Schluckauf seiner Cloud-Dienste. Ein Leser informierte mich bereits gegen 14:29 Uhr, dass Microsoft Entra seit 2 Stunden nicht mehr erreichbar sei. Da ich einige Tage unterwegs war, konnte ich nicht reagieren. Daher die Informationen, was inzwischen bekannt ist, kurz nachgereicht.
Erste Lesermeldungen
David S. meldete sich per Mail mit dem Betreff "MS Entra down" und teilte mir um 14:29 Uhr mit, dass "man seit knapp 2 Std. nicht mehr auf MS Entra kommt" (danke für den Hinweis). Er bekommt beim Versuch, die Dienstseite aufzurufen nur folgende Fehlermeldung: Die aufgerufene Seite ist leider nicht erreichbar, heißt es lapidar.

Inzwischen gibt es eine Bestätigung von Microsoft – David hat mir folgenden Auszug als Grafik zugeschickt. Unter der Issue ID MO842351 gibt Microsoft an, dass Nutzer Probleme hätten, diverse Microsoft 365-Dienste zu erreichen. Die Störung scheint wohl weltweit zu bestehen, obwohl Microsoft schreibt, dass die Probleme nur bestimmte Nutzer beträfen.

Auf Facebook meldete jemand ebenfalls: Microsoft hat in Azure und mit sämtlichen 365 Diensten grade massiv mit Netzwerk, Delay und weiteren Problemen zu kämpfen. Auf X teilt Microsoft 365 Status (@MSFT365Status) vor gut einer Stunde mit, dass Microsoft aktuell Probleme beim Zugriff auf verschiedene Dienste und Features untersucht.
We're currently investigating access issues and degraded performance with multiple Microsoft 365 services and features. More information can be found under MO842351 in the admin center.
Manche Nutzer können die Dienste überhaupt nicht erreichen, bei anderen gibt es Leistungsprobleme. Auf allestoerungen.de sieht man, dass die Störung so gegen 13:00 Uhr deutscher Zeit beginnt, und wieder am Abklingen zu sein scheint.
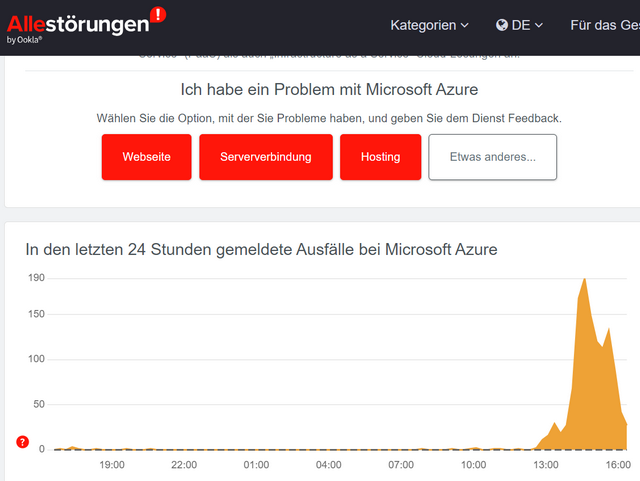
Laut heise teilt Microsoft über seine Azure-Statusseite mit, dass seit ca. 15:13 MESZ (13:13 UTC) ein Netzwerkproblem an allen Azure-Standorten besteht, das zu Zeitüberschreitungen beim Verbindungsversuch mit Diensten führen kann, die in Microsofts Cloud gehosted sind. Eine Ursache für die Störung ist noch nicht bekannt.
Nachträge: Statusseite down, Fix wird ausgerollt
Ich habe gegen 17:13 Uhr versucht, die Microsoft Azure-Statusseite aufzurufen, bekomme aber die folgende Fehlermeldung:
Our services aren't available right now
We're working to restore all services as soon as possible. Please check back soon.
20240730T151128Z-16b8f8f97cfjwrzdwh74uzn50n00000005m000000000qeuz
Auf X schreibt Microsoft dagegen, dass man haben Abhilfemaßnahmen getroffen und Benutzeranfragen umgeleitet habe, um Abhilfe bezüglich der Störung zu schaffen. Zumindest in meinem Bereich hat das aber nicht geholfen, da ich nicht mal auf die Statusseite komme.
Ergänzung: Ich hatte inzwischen die Möglichkeit, auf die Azure Statusseite zu kommen und habe im Azure-Statusverlauf folgende Information gefunden.
What happened?
Between approximately at 11:45 UTC and 19:43 UTC on 30 July 2024, a subset of customers may have experienced issues connecting to a subset of Microsoft services globally. Impacted services included Azure App Services, Application Insights, Azure IoT Central, Azure Log Search Alerts, Azure Policy, as well as the Azure portal itself and a subset of Microsoft 365 and Microsoft Purview services.
What do we know so far?
An unexpected usage spike resulted in Azure Front Door (AFD) and Azure Content Delivery Network (CDN) components performing below acceptable thresholds, leading to intermittent errors, timeout, and latency spikes. While the initial trigger event was a Distributed Denial-of-Service (DDoS) attack, which activated our DDoS protection mechanisms, initial investigations suggest that an error in the implementation of our defenses amplified the impact of the attack rather than mitigating it.
How did we respond?
Customer impact began at 11:45 UTC and we started investigating. Once the nature of the usage spike was understood, we implemented networking configuration changes to support our DDoS protection efforts, and performed failovers to alternate networking paths to provide relief. Our initial network configuration changes successfully mitigated majority of the impact by 14:10 UTC. Some customers reported less than 100% availability, which we began mitigating at around 18:00 UTC. We proceeded with an updated mitigation approach, first rolling this out across regions in Asia Pacific and Europe. After validating that this revised approach successfully eliminated the side effect impacts of the initial mitigation, we rolled it out to regions in the Americas. Failure rates returned to pre-incident levels by 19:43 UTC – after monitoring traffic and services to ensure that the issue was fully mitigated, we declared the incident mitigated at 20:48 UTC. Some downstream services took longer to recover, depending on how they were configured to use AFD and/or CDN.
What happens next?
Our team will be completing an internal retrospective to understand the incident in more detail. We will publish a Preliminary Post Incident Review (PIR) within approximately 72 hours, to share more details on what happened and how we responded. After our internal retrospective is completed, generally within 14 days, we will publish a Final Post Incident Review with any additional details and learnings. To get notified when that happens, and/or to stay informed about future Azure service issues, make sure that you configure and maintain Azure Service Health alerts – these can trigger emails, SMS, push notifications, webhooks, and more: https://aka.ms/ash-alerts. For more information on Post Incident Reviews, refer to https://aka.ms/AzurePIRs. Finally, for broader guidance on preparing for cloud incidents, refer to https://aka.ms/incidentreadiness.









Keinerlei Probleme, wir können alle Dienste erreichen.
Gibt es eigentlich einen Kalender bzw. Übersicht, wie oft in den letzten Jahren die MS Dienste Down / gestört waren?
Gefühlt mindestens 1x jeden Monat.
Ganz einfach M65 = 65 Tage pro Jahr funktioniert es problemlos.
Auch hier keine Probleme feststellbar.
hihi… ich mag solche Optimisten wie Dich… 1x pro Monat… looool.
Von MINDESTENS war ja die rede ;)
Ich bin auch nur für die "eigene" Cloud im Unternehmen. Aber wenn es einen Dienst gibt, der solchen Downtimes trackt, teile ich den gerne mal mit der Geschäftsleitung.
Es werden zwar häufig Probleme bei 365 gemeldet, aber wir können die in 99% der Fälle nicht nachvollziehen, warum auch immer. Ggf regional begrenzt Probleme die aber global gemeldet werden?
Hier keine Probleme festzustellen.
keine Probleme bei uns. Alle Dienste erreichbar. Den ganzen Tag über.
Im Südwesten läuft der komplette Azure Stack
Kann bestätigt werden. Ins Adminportal einzuloggen dauerte eine Ewigkeit – über verschiedene Provider getestet… Wenn man Geduld hatte, konnte man nach ein paar Minuten den Admin-User eingeben; dann wieder einige Minuten warten, dann Passwort; dann wieder ein paar Minuten warten für 2FA. grob über den Daumen.dauerte ein Login gute 15 Minuten, aber man kam wenigstens rein.
Das klingt nach massivem Paketverlust.
Kann man in Wireshark was sehen?
Naja, ist ja nicht so schlimm und morgen wird es wieder funktionieren. Einfach keinen Kopf machen.
Ich bin ja nicht schuld, sondern Microsoft.
Habe Wireshark nicht angeworfen. ist ja MS und Cloud…. da kann man halt nichts machen ;-)
(früher, wenn man im Onprem-Exchange etwas nicht innerhalb 5 Minuten anpassen konnte, kriegte man als Admin noch einen richtigen ZS.
Warum die Geschäftsleitungen aber heutzutage solche Downtimes als selbstverständlich sehen, ist mir schleierhaft – wie gesagt, früher kriegte der Admin schon nach ein paar Minuten eins aufs Dach. So gesehen müssen wir Admins ja eigentlich MS dankbar sein, kann man halt nichts machen ;-)
das erinnert mich an einen Kunden, der sich bei einem M365 Ausfall sehr beschwerte und damit drohte zu einen anderen M365 Anbieter zu wechseln, weil wir offensichtlich unsere Infrastruktur nicht im Griff haben ;-)
"So gesehen müssen wir Admins ja eigentlich MS dankbar sein, kann man halt nichts machen"
Ich fürchte das das Teil des Geschäftsmodells von MS ist.
Die GL kann sagen: Wir haben das genauso gemacht wie tausend andere Unternehmen auch. Das kann also nicht falsch sein.
Wenn es jetzt nicht klappt, liegt es nicht in unserer Verantwortung
Hätten wir Linux genommen, hätten wir die Verantwortung zu tragen…
Und wie gesagt.
Unsere Versicherung sagt, dass wir 24h ganz ohne IT auskommen. (OK, die LKWs stehen sehr schnell Schlange und kippen uns das Zeugs mitten auf den Hof, weil sie den nächsten Auftrag haben.)
Ich wäre sehr dafür das Gü einen extra Blog für MS Dienste aufmacht die down sind.
(Und für Updates von dieser Firma bitte gerne auch nochmal)
:-)
Idee wäre gut, aber Günter will sich doch bald zur Ruhe setzen… und sich nicht noch mehr Arbeit aufhalsen ;-)
Ich gebe dir voll recht. Anno 2000 fand ich Gü's Topic als minderjähriger auch geil – da hatte er gerade sein HTM4 Taschenbuch publiziert.
Stand heute redet er nur MS ist kacke – damals Ballmer heute Nadella.
Ok – Fridolin ;)
Der Spamschutz scheint auch was abbekommen zu haben.
Ich habe die letzte Zeit wieder reichlich "Viagra-Angebote" von einer -(@)hotmail.com-Adresse".
nene, dat muss so, Du stehst auf meinem Verteiler … Mhmm, noch nicht geklickt, können wir am Marketing etwas verbessern?
igitt
Die halbe verfluchte MS-Cloud scheint schon wieder down zu sein. Ich habe auch Probleme mit Lexware Diensten und auch die TSE für die Kasse funktioniert nicht mehr. Homepage von Lexware auch nicht erreichbar. Wenn man sie pingt bekommt man eine Fehlermeldung von einem MS-Server zurück. Habe die Lexware Partnerbetreuung angeschrieben. Mal sehen, was die dazu sagen. Mit dieser Cloud hat Microsoft die Büchse der Pandora geöffnet. Ich bin froh, dass ich mein Zeug, soweit möglich, on prem habe.
Hatte keine Störungen, alles normal. Irgendwas mach ich falsch, dass ich nicht ins Klagelied der Betroffenen einstimmen kann. Njur was?
Ich hatte auch keine Störungen.
Vielleicht liegt es an unserem Verzicht von Microsoft Produkten? :)
"Momentan kämpft Microsoft wohl mit einem Schluckauf …"
Der ist gut. Microsoft hat doch täglich irgend ein Schluckauf.
deswegen kann man auch Inhalten cachen, ob OneDrive, Outlook oder Teams. Dann kann man weiterarbeiten und dass sogar ungestört, denn es kommt nix neues hinzu und Teams bimmelt auch nicht mehr.
Die Cloud Störungen dürften signifikant daher zu höherer Produktivität führen. Bis auf Whatsapp, wenn das noch ausfällt, ist es wie Weihnachten und Ostern für den Chef!
Laut MS eine Cyber-Attacke:
https://www.bbc.com/news/articles/c903e793w74o
Wir hatten das im Microsoft Defender gemerkt. Der Aufruf von Assets – Devices dauerte ewig und schlug dann fehl mit dem Hinweis " no data available"
Zuerst denkt man ja immer, es liegt am eigenen Umfeld.
In den von uns verwendeten Regionen (North Europe und West Europe) sind auch keine Ausfälle aufgetreten.
So einen Klaud-Verfügbarkeitsrotz gabs bei mir die letzten 20 Jahre onprem nie und nimmer. 99,x – da lachen die Hühner. Aber sie wollten es so haben.
Das geht sowas von locker.
99.3 bei 5×11 (Tage a 11 Std., 8 – 17) ist der Std Vertrag.
Der Cxx Level mit der Eechtabteilzng wissen im Normalfall ja nicht das IT immer 7x24x365 läuft.
Die Erwartung haben sie, das Geld nie.
Darum wird die Verfügbarkeit korrekt nach Vertrag ausgewiesen.
Seit 35 Jahren in der IT, als SysAdmin, SAP und CIO.
Ich habe aufgeben, halte die Kopie des Vetrags inkl. Highligthing der entsprechenden Stellen und meinen Mails zum Thema parat.
Zwischendurch gibt eine Zusatzgewinn, innerhalb eines Monats nach einem Vorfall, dass mann dann die Ausfallsicherheit der Zugänge oder so bekommt…..
Das erspart mir extrem viel Nerven