[German]Currently Microsoft is struggling with a hiccup in its cloud services. A reader informed me at around 2:29 pm (Central European Time) that Microsoft Entra had been unavailable since 2 hours. Here is a brief update on what is now known.
[German]Currently Microsoft is struggling with a hiccup in its cloud services. A reader informed me at around 2:29 pm (Central European Time) that Microsoft Entra had been unavailable since 2 hours. Here is a brief update on what is now known.
First reader reports
David S. contacted me by e-mail with the subject "MS Entra down" and informed me at 2:29 p.m. that "I have not been able to access MS Entra for almost 2 hours" (thanks for the tip). He only gets the following error message when trying to access the service page: Sorry, the page you are trying to access is not available, it says tersely. Here is a screenshot of the German message.

In the meantime there is a confirmation from Microsoft – David has sent me the following excerpt as a graphic. Under the issue ID MO842351, Microsoft states that users are having problems accessing various Microsoft 365 services. The disruption seems to be worldwide, although Microsoft writes that the problems only affect certain users.

Someone also reported on Facebook: Microsoft is currently experiencing massive network, delay and other problems in Azure and with all 365 services. On X, Microsoft 365 Status (@MSFT365Status) announced just over an hour ago that Microsoft is currently investigating problems with access to various services and features.
We're currently investigating access issues and degraded performance with multiple Microsoft 365 services and features. More information can be found under MO842351 in the admin center.
Some users cannot reach the services at all, others are experiencing performance problems. On allestoerungen.de you can see that the disruption starts around 13:00 German time and seems to be subsiding again.
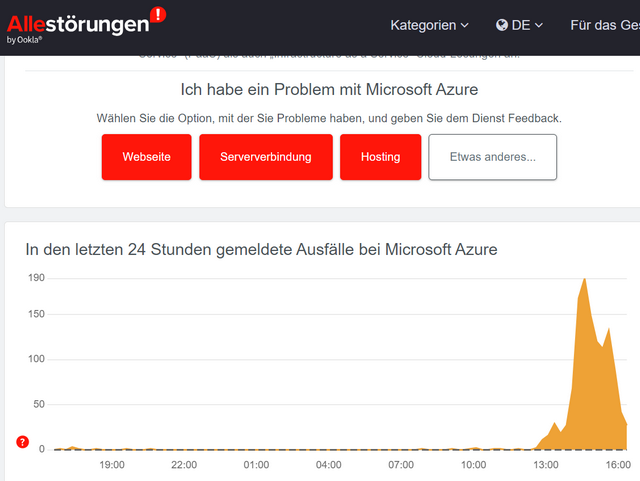
According to German site heise Microsoft informed on their Azure status site, that since approx. 15:13 CEST (13:13 UTC) there has been a network problem at all Azure locations, which can lead to timeouts when trying to connect to services hosted in Microsoft's cloud. A cause for the issue is not yet known.
Statuspage also down, first mitigations
I tried to access the Microsoft Azure status page at around 5:13pm (CET), but I get the following error message:
Our services aren't available right now
We're working to restore all services as soon as possible. Please check back soon.
20240730T151128Z-16b8f8f97cfjwrzdwh74uzn50n00000005m000000000qeuz
On the other hand, Microsoft writes on X that they have taken corrective measures and redirected user requests to remedy the problem. However, at least in my area this has not helped, as I can't even access the status page.
Addendum: I was able to access the Azure status history and found the following information.
What happened?
Between approximately at 11:45 UTC and 19:43 UTC on 30 July 2024, a subset of customers may have experienced issues connecting to a subset of Microsoft services globally. Impacted services included Azure App Services, Application Insights, Azure IoT Central, Azure Log Search Alerts, Azure Policy, as well as the Azure portal itself and a subset of Microsoft 365 and Microsoft Purview services.
What do we know so far?
An unexpected usage spike resulted in Azure Front Door (AFD) and Azure Content Delivery Network (CDN) components performing below acceptable thresholds, leading to intermittent errors, timeout, and latency spikes. While the initial trigger event was a Distributed Denial-of-Service (DDoS) attack, which activated our DDoS protection mechanisms, initial investigations suggest that an error in the implementation of our defenses amplified the impact of the attack rather than mitigating it.
How did we respond?
Customer impact began at 11:45 UTC and we started investigating. Once the nature of the usage spike was understood, we implemented networking configuration changes to support our DDoS protection efforts, and performed failovers to alternate networking paths to provide relief. Our initial network configuration changes successfully mitigated majority of the impact by 14:10 UTC. Some customers reported less than 100% availability, which we began mitigating at around 18:00 UTC. We proceeded with an updated mitigation approach, first rolling this out across regions in Asia Pacific and Europe. After validating that this revised approach successfully eliminated the side effect impacts of the initial mitigation, we rolled it out to regions in the Americas. Failure rates returned to pre-incident levels by 19:43 UTC – after monitoring traffic and services to ensure that the issue was fully mitigated, we declared the incident mitigated at 20:48 UTC. Some downstream services took longer to recover, depending on how they were configured to use AFD and/or CDN.
What happens next?
Our team will be completing an internal retrospective to understand the incident in more detail. We will publish a Preliminary Post Incident Review (PIR) within approximately 72 hours, to share more details on what happened and how we responded. After our internal retrospective is completed, generally within 14 days, we will publish a Final Post Incident Review with any additional details and learnings. To get notified when that happens, and/or to stay informed about future Azure service issues, make sure that you configure and maintain Azure Service Health alerts – these can trigger emails, SMS, push notifications, webhooks, and more: https://aka.ms/ash-alerts. For more information on Post Incident Reviews, refer to https://aka.ms/AzurePIRs. Finally, for broader guidance on preparing for cloud incidents, refer to https://aka.ms/incidentreadiness.