
 KI-Lösungen wie Microsofts Copilot, aber auch Anthropic oder OpenAI ChatGPT erweisen sich immer mehr als latentes Sicherheitsrisiko. Es vergeht eigentlich kein Tag, an dem nicht eine neue Sicherheitslücke oder ein Weg zum Umgehen der in den LLMs eingebauten Sicherheitsschranken publik wird. Hinzu kommt der Beschiss durch das Marketing der AI-Anbieter. Ich habe nachfolgend eine kleine Zusammenfassung erstellt, was mir so die Tage an entsprechenden Themen untergekommen ist.
KI-Lösungen wie Microsofts Copilot, aber auch Anthropic oder OpenAI ChatGPT erweisen sich immer mehr als latentes Sicherheitsrisiko. Es vergeht eigentlich kein Tag, an dem nicht eine neue Sicherheitslücke oder ein Weg zum Umgehen der in den LLMs eingebauten Sicherheitsschranken publik wird. Hinzu kommt der Beschiss durch das Marketing der AI-Anbieter. Ich habe nachfolgend eine kleine Zusammenfassung erstellt, was mir so die Tage an entsprechenden Themen untergekommen ist.
Antrophic Claude Mythos: Der große Marketing-Beschiss
Vor einer Woche jagte die Schlagzeile durch die Medien, dass Antrophic Claude Mythos als neues Sprachmodell vorgestellt habe. Das neue Anthropic KI-Modell Claude Mythos überbietet alle Konkurrenten in seinen Fähigkeiten. Claude Mythos soll erstmals Schwachstellen in Software selbständig ermittelt haben und kann sogar Exploits entwickeln. Dieses Modell bleibt laut Hersteller daher aus Sicherheitsgründen auf Experten beschränkt.
Das Manager Magazin veröffentlichte vor einer guten Woche den Artikel Neues Anthropic-Modell versetzt Regierungen und CEOs in Alarmstimmung. Sicherheitsorganisationen wie das BSI, Regierungen und Unternehmen waren aufgescheucht und versuchten die Implikationen abzuschätzen.
Sicherlich ist der Fortschritt bei Claude Mythos beeindruckend. Mit ist vor einer Woche obiger Tweet untergekommen, der dann doch etwas die Luft aus dem aufgepusteten Ballon raus lässt. Die Botschaft des Tweets: Es war vor allem ein "Marketing-Pitch", denn viele der Tausende durch das Modell in älterer Software entdeckten Bugs und Schwachstellen lassen sich nicht ausnutzen. Und die Berichte über schwerwiegende Zero-Day-Schwachstellen stützen sich lediglich auf 198 manuelle Überprüfungen. Tom's Hardware hat einige Details in diesem Artikel (leider Paywall) zusammen getragen.
Schwachstelle in wolfSSL
Dann gab nach die Meldung, dass Anthropic Sicherheitsforscher mittels KI eine Schwachstellen in wolfSSL gefunden hätten. wolfSSL, eine Bibliothek, die in Produkten von VPN-Apps und Heimroutern bis hin zu Fahrzeugsystemen, Stromnetzinfrastruktur und militärischen Systemen zum Einsatz kommt.
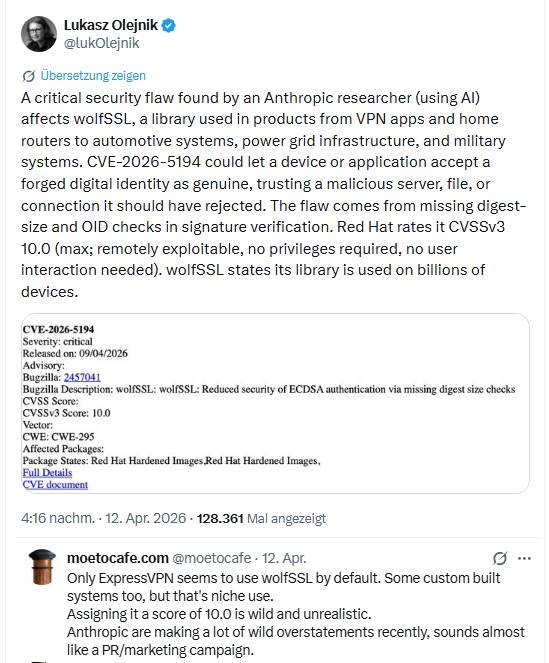
In obigem Tweet weist Lukasz Olejnik auf eine von einem Forscher bei Anthropic (mithilfe von KI) entdeckte kritische Sicherheitslücke CVE-2026-5194 hin, die wolfSSL betrifft. wolfSSL ist eine Bibliothek, die in Produkten von VPN-Apps und Heimroutern bis hin zu Fahrzeugsystemen, Stromnetzinfrastruktur und militärischen Systemen zum Einsatz kommt.
CVE-2026-5194 könnte dazu führen, dass ein Gerät oder eine Anwendung eine gefälschte digitale Identität als echt akzeptiert und einem böswilligen Server, einer Datei oder einer Verbindung vertraut, die es eigentlich hätte ablehnen müssen. Die Schwachstelle ist auf fehlende Überprüfungen der Digest-Größe und der OID bei der Signaturprüfung zurückzuführen. Red Hat bewertet den Bug mit CVSSv3 10,0 (maximal; remote ausnutzbar, keine Berechtigungen erforderlich, keine Benutzerinteraktion erforderlich).
wolfSSL gibt an, dass die Bibliothek auf Milliarden von Geräten verwendet wird. Ein Nutzer ordnet das Ganze aber gleich ein: Nur Express VPN setze wolfSSL standardmäßig ein. Das Ganze sei eine PR-Kampagne.
AI-Agenten und die MCP-Probleme
Ein Team von Sicherheitsforschern hat 100 AI Agent (Model Context Protocol, MCP)-Server im Hinblick auf Sicherheit geprüft. Darunter waren auch die von Anthropic und Microsoft gepflegten Referenzimplementierungen, die als "Goldstandard" gelten.
Laut dem auf GitHub veröffentlichten Bericht erhielt jeder vom Hersteller gepflegte Server, der Tools offenlegte, die Note "F" (ungenügend).
- Im gesamten Ökosystem erhielten 71 % der Server die Note F.
- Keiner erhielt die Note A.
Die Sicherheitsforscher identifizierten insgesamt 893 Befunde auf 41 Servern, die 485 Tools bereitstellten, darunter 163 Fälle einer neuen Schwachstellenklasse, die die Forscher als "halluzinationsbasierte Schwachstellen" (HBVs) bezeichnen. Das sind Sicherheits-Schwachstellen, die für die Ausführung von LLM-gesteuerten Tools spezifisch sind, bei denen vage oder mehrdeutige Tool-Definitionen dazu führen, dass das Sprachmodell übermäßige Berechtigungen gewährt, Daten falsch weiterleitet oder sich unvorhersehbar verhält.
Die von den Sicherheitsforschern verwendeten Scanner identifiziert die genauen strukturellen Voraussetzungen – unbegrenzte String-Parameter, fehlende Schema-Validierung, vage Bereichsgrenzen –, die zu den CVEs der RCE-Klasse führten, die Anfang 2026 gegen MCP-Server offengelegt wurden (CVE-2025-68143, CVE-2025-68144, CVE-2025-9611).
Diese Ergebnisse zeigen, dass die MCP-Spezifikation standardmäßig anfällig ist. Dazu passt auch der The Register-Beitrag Anthropic won't own MCP 'design flaw' putting 200K servers at risk, researchers say, in dem es um eine MCP-Design-Schwäche im MCP geht.
ChatGPT-Bug schmuggelt Daten über DNS
OpenAI versucht ja Datenabflüsse in ChatGPT zu vermeiden und hat dazu einige Sicherheitsschranken im Produkt eingebaut. Dabei hat man aber wohl den DNS-Traffic übersehen. Sicherheitsforscher von Check Point haben festgestellt, dass eine einzige böswillige Eingabeaufforderung (Prompt) einen versteckten Datenabflusskanal innerhalb einer normalen ChatGPT-Konversation aktivieren kann. Das Ganze wurde in diesem Blog-Beitrag dokumentiert, The Register hatte es hier aufgegriffen.
KI vergrößert die Angriffsfläche
Durch KI-gestützte Code-Generierung läuft die gesamte Software-Branche in ein riesiges Problem, was außerhalb von Expertenkreisen noch kaum gesehen wird. Wir haben keinen Engpass in der Code-Erstellung, der Flaschenhals ist beim Test des so erzeugten Programmcodes. Die Entwickler "ersaufen" in der Menge des generierten Codes, haben aber keine Zeit mehr, das vernünftig zu testen.
Man kann es auch drastisch ausdrücken: Da wird von vielen AI-Protagonisten an der falschen Stelle applaudiert. Nicht die Codegenerierung begrenzt die Produktivität, sondern die Fähigkeit, die Ergebnisse auch sauber zu testen. Wenn KI da nicht noch eine Menge Briketts drauf legt, wird das alles nichts.
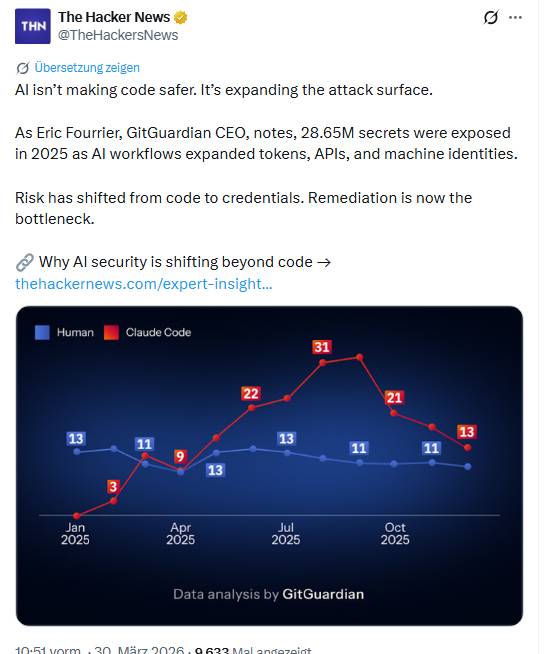
The Hacker News schreibt in obigem Tweet und diesem Artikel, dass KI Code nicht sicherer macht, sondern vielmehr die Angriffsfläche vergrößert. Eric Fourrier, CEO von GitGuardian, sagt, dass im Jahr 2025 bereits 28,65 Millionen Geheimnisse offengelegt wurden, da KI-Workflows die Anzahl von Tokens, APIs und Maschinenidentitäten erhöhten. Das Risiko habe sich vom Code auf Anmeldedaten verlagert. Die Behebung von Sicherheitslücken sei nun der Engpass.
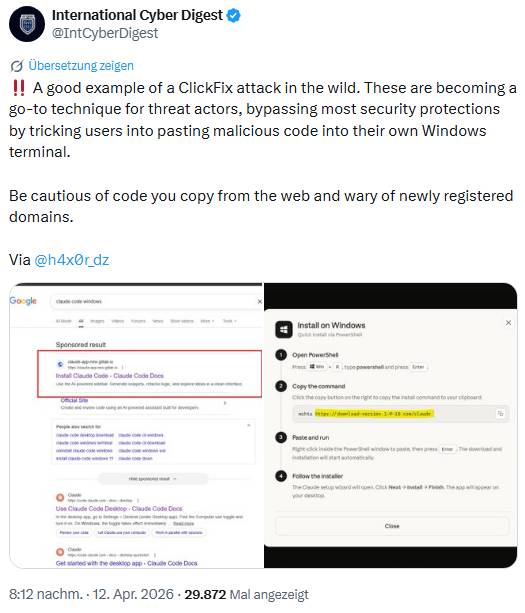
Hinzu kommt das Problem, dass sich LLMs durch eingebettete Anweisungen (Prompts) für eine ClickFix-Attacke missbrauchen lassen – der Besuch einer Webseite mit solchen Anweisungen durch einen Agenten oder ein LLM reicht. Und manche Leute sind dämlich genug, alles einzutippen, was ein LLM so von sich gibt. Obiger Tweet zeigt ein Beispiel für einen ClickFix-Angriff. Dem Nutzer wird ein Befehl zum Download eines Sprachmodells angeboten, welches schädliche Software installiert. Diese Methode wird für Angreifer immer beliebter, da sie die meisten Sicherheitsvorkehrungen umgeht, indem sie Nutzer dazu verleitet, bösartigen Code in ihr eigenes Windows-Terminal einzufügen, heißt es in obigem Tweet.
Die Frage nach Verantwortlichkeiten?
Wenn KI einen immer größeren Anteil des Produktionscodes erstellt, dieser Code jedoch versagt, Schwachstellen beinhaltet oder einen Ausfall hervorruft, bleibt die Frage nach der Verantwortlichkeit unklar. Pramin Pradeep, CEO von BotGauge, stellt folgende Fragen:
- Ist der Entwickler für Code verantwortlich, den er nicht vollständig selbst geschrieben hat?
- Ist der KI-Anbieter für das verantwortlich, was sein Modell generiert hat?
- Oder liegt die Haftung bei dem Unternehmen, das die KI eingesetzt hat?
Viele Unternehmen stellen fest, dass ihre Prüfpfade für von Menschen geschriebenen Code konzipiert wurden. Oft können sie nicht eindeutig nachvollziehen, wie KI-gestützter Code generiert, überprüft oder validiert wurde. Dies beginnt, so Pramin Pradeep, die Sichtweise von Unternehmen auf das Testen zu verändern. Es geht zunehmend weniger um Produktivität und mehr um Governance.
Pramin Pradeep, CEO von BotGauge, arbeitet mit Entwicklerteams zusammen, die mit diesem Wandel konfrontiert sind. Seine Sichtweise: Wenn KI-Code schreibt, benötigen Unternehmen nun Systeme, die KI-generierten Code validieren und eine klare Rückverfolgbarkeit gewährleisten können. Da sind noch einige Hausaufgaben in Unternehmen zu machen. Der EU AI Act sieht die Verantwortlichkeiten klar bei den jeweiligen Herstellern (also Anbietern von KI-Lösungen) aber auch bei den KI-Anwendern.
SANS Institute und andere veröffentlichen Strategiepapier
Die Tage habe ich die Information per E-Mail erhalten, dass das SANS Institute und die Cloud Security Alliance (CSA) gemeinsam mit [un]prompted und dem OWASP GenAI Security Project den Report "The AI Vulnerability Storm: Building a Mythos-Ready Security Program" veröffentlicht haben. Dieses kostenlose Strategie-Briefing gibt CISOs und Sicherheitsverantwortlichen ein umsetzbares Framework an die Hand, um auf das immer schneller werdende Tempo der Entdeckung und Ausnutzung von Schwachstellen durch KI zu reagieren.
Das Briefing dokumentiert eine rasante Eskalation der offensiven KI-Fähigkeiten im vergangenen Jahr. Im Juni 2025 wurde XBOW als erstes autonomes System Spitzenreiter der US-Rangliste von HackerOne und übertraf damit alle menschlichen Hacker auf der Plattform. Im August 2025 fand die AI Cyber Challenge der DARPA innerhalb von vier Stunden 54 Schwachstellen in 54 Millionen Codezeilen. Im November 2025 gab Anthropic bekannt, dass eine vom chinesischen Staat geförderte Gruppe KI eingesetzt hatte, um autonom vollständige Angriffsketten – von der Aufklärung bis zur Datenexfiltration – bei etwa 30 globalen Zielen durchzuführen.
Im Februar 2026 meldete Anthropic mithilfe von Claude Opus 4.6 mehr als 500 Schwachstellen mit hohem Schweregrad in Open Source-Software. Sysdig dokumentierte einen KI-basierten Angriff, der innerhalb von acht Minuten Administratorrechte erlangte. Die Zahl der Schwachstellenmeldungen stieg bei den Linux-Kernel-Betreuern von zwei auf zehn pro Woche.
Mythos stellt laut Mitteilung an mich einen weiteren Meilenstein dar. In internen Tests habe das Modell 181 funktionierende Exploits gegen Firefox-Schwachstellen generiert, während das bisher beste Modell unter denselben Bedingungen nur zweimal erfolgreich war. Das Modell erzielte eine Erfolgsquote von 72 Prozent bei Exploits und demonstrierte die Fähigkeit, mehrere Schwachstellen ohne menschliche Anleitung zu einzelnen Exploit-Pfaden zu verketten.
Laut der Zero Day Clock ist die durchschnittliche Zeit von der Offenlegung einer Schwachstelle bis zur bestätigten Ausnutzung im Jahr 2026 auf weniger als einen Tag gesunken, gegenüber 2,3 Jahren im Jahr 2019. Das veröffentlichte Briefing umfasst ein 13-Punkte-Risikoregister, das vier Branchen-Frameworks zugeordnet ist (OWASP LLM Top 10 2025, OWASP Agentic Top 10 2026, MITRE ATLAS und NIST CSF 2.0), eine Tabelle mit 11 Sofortmaßnahmen und straffen Zeitplänen, 10 diagnostische Fragen für CISOs zur Bewertung ihres aktuellen Sicherheitsprogramms sowie einen Abschnitt mit einer Zusammenfassung für Vorstände.
KI-gestützte Tools zur Schwachstellenerkennung können mittlerweile funktionierende Exploits in einem Tempo generieren, das die Patch-Zyklen von Unternehmen übertrifft. Jeder Patch wird zudem zu einer Blaupause für Exploits, da KI das Patch-Diffing und das Reverse Engineering von Korrekturen beschleunigt.
Defensive Teams, die keine KI-Agenten einsetzen, sehen sich einer wachsenden Kompetenzlücke gegenüber KI-gestützten Angreifern gegenüber, unabhängig von ihren bestehenden technischen Fähigkeiten. Das Briefing stuft dies ebenso sehr als kulturelle wie als technologische Herausforderung ein.
Der EU AI Act tritt im August 2026 in Kraft und führt automatisierte Audits, Vorfallmeldungen sowie Cybersicherheitsanforderungen im Zusammenhang mit KI ein. Wenn KI Schwachstellen zu erschwinglichen Kosten aufspüren kann, verschiebt sich der Maßstab dafür, was als angemessene Verteidigungsmaßnahme gilt. Dies bringt für Organisationen, die sich nicht anpassen, direkte Governance- und Haftungsrisiken mit sich.
Kritische Sicherheitslücke in Claude Code
Sicherheits-Experten sind auf eine kritische Sicherheitslücke in Claude Code gestoßen. Sogenannte "Deny"-Regeln, die Missbrauch verhindern sollen, können unbemerkt umgangen werden, da Sicherheitsprüfungen zu viele Token verbrauchen. Daher verzichtet Anthropic in bestimmten Konstellationen auf weitere Prüfungen. Die Details hat Adversa in diesem Blog-Beitrag offen gelegt.
Auf die Lieferkettenangriffe (Axios & Co.) bin ich in diversen Blog-Beiträgen ja bereits eingegangen. Es sieht so aus, als ob die IT durch Angreifer sturmreif geschossen wird – und die Zunft ist dämlich genug, durch KI-Einsatz weitere riesige Sicherheitslöcher aufzureißen, damit alles "effizienter" wird.
Wie KI-Agent Luna gescheitert ist
Die Kollegen von Golem haben vor einigen Tagen im Artikel KI-Agent Luna eröffnet Laden und scheitert an der Realität über ein Experiment in San Franzisko berichtet. Ein KI-Agent bekam ein Budget von 100.000 US-Dollar und sollte einen Laden eröffnen und führen. Das Ganze war aber nicht so erfolgreich, dass LLM versuchte Aufträge für Malerarbeiten nach Afghanistan zu vergeben, lehnte in Mitarbeitergesprächen Bewerber wegen fehlender Erfahrung ab, und so weiter. Die Schöpfer gehen nicht davon aus, dass der KI-Agent Luna jemals Gewinne macht.
Windows Recall weiter unsicher
Ich hatte es die Tage bereits bei Tom Warren in diesem Tweet und im The Verge-Artikel Microsoft faces fresh Windows Recall security concerns (erfordert Abo) gelesen. Ein Sicherheitsforscher hat ein Tool entwickelt, mit dem sich Daten aus Recall extrahieren lassen. Golem hat das Thema im Artikel Totalrecall Reloaded: Tool zeigt Schwachstelle in Windows Recall aufgegriffen. Die Kollegen von Dr. Windows schreiben in diesem Beitrag, dass Microsoft die Sicherheitslücke dementiert.
Meine Meinung: Es ist und bleibt halt Microslop. Dazu passt auch die Meldung Vorbild OpenClaw: Copilot soll zum vollständig autonomen KI-Assistenten werden auf Dr. Windows.









Man glaubt, hofft, das es irgendwie gut ausgehen möge.
Wie sollte man sonst morgens aufstehen, optimistisch sein und weitermachen wollen?
Hoffen darf man, aber alle Weichen stehen auf Kollaps… ist meine persönliche Vermutung!
Die Welt wird sich weiterdrehen mit oder ohne KI ;-P Möge die nächste Spezies schlauer sein.
/Edit/
****************************************
a sie die meisten Sicherheitsvorkehrungen umgeht, indem sie Nutzer dazu verleitet, bösartigen Code in ihr eigenes Windows-Terminal einzufügen, heißt es in obigem Tweet.
****************************************
Das ist doch bei mehr als 98% der Malware so… also kein KI Problem ansich. es gibt zwar DriveBy Malware & Co. , aber die macht in der freien Wildbahn keine 2% aus.
Es braucht immer den DAU der das zuläßt. ob das jetzt im klassischen Sinn passiert oder über KI macht da keinen Unterschied!
Diese Lücke ist auch nicht patchbar.
Wenn man alles so heiß isst wie es gekocht wird hat man ständig Brandblasen am Sprachrohr.
Ich erwarte für 2026 keinen Weltuntergang durch LLMs. Weil wir seit 2026 ja endlich auch wissen wie man hinter dem Mond lebt.
Es geht doch eh nur um das Abgreifen von Daten.
Künstliche Intelligenz würde nämlich, wenn man mal genau nachdenkt (was KI nicht kann),
auch implementieren, dass es künstliches Leben geben würde.
Gruß
R.G.
"LLMs are awesome — finally I can watch adult Japanese vacation videos live."
"… der große Marketing-Beschiss."
Trotzdem erfolgreich, wendet sich dieses Marketing an CEOs und BWLer. Die IT-Abteilung hat die Klappe zu halten.
So ist es. Wenn selbst die es merken, ist das Kind längst im Brunnen.
https://agentsid.dev/
Also der MCP-Test ist auch nur Werbung für ein Tool, dass das Sicherheit verkauft.
Das größte Problem daran ist, das diese KIs und LLMs in der Hand von börsennotierten Privatunternehmen ist…
Schlimmer wäre natürlich, wenn ist in staatlicher Obhut (Amerika, Russland, Nordkorea oder China) wäre natürlich die Schlimmste.
Dazu siehe z.B. ganz aktuell hier https://www.heise.de/news/Anthropic-und-US-Regierung-wieder-im-Gespraech-ueber-Zusammenarbeit-11263461.html
Da in diesen Länder (Russland Nordkorea China und mittlerweilen auch Amerika) der Staat über das Wohl und Verderb der Privatunternehmen entscheidet ist es defacto aber in Staatshand ;-P Da stellt sich kein Privatunternehmen gegen staatliche Anordnungen!
Und trotzdem dreht sich die Erde noch weiter…
Ich finde KI super, das Gejammere ist irgendwie typisch deutsch. Man stelle sich vor: OpenDesk Weiterentwicklung und Umstellung der Behörden auf eigene Systeme, unterstützt durch US KI Systeme.
Genial.
Außerdem: der Sieg über die Knappheit des Wissens. Ja, Experten werden Rendite verlieren und ja, Löhne werden sinken und viele Jobs wird es nicht mehr geben aber mal ganz ehrlich: Doorkeeper spielen und die Hand aufhalten ist nicht sehr kreativ und bremst die Gesamtentwicklung aus. Wir müssen uns etwas besseres einfallen lassen.
Kritik oder "Gejammere", wie Du es nennst, als "typisch deutsch" abzutun, ist so was von typisch deutsch, zumal eine Vielzahl der im Artikel verlinkten Quellen wie theverge, tomshardware, theregister oder thehackernews offensichtlich nicht aus Deutschland stammen.
die Angst der Beteiligten, Herrenwissen zu verlieren, das steckt dahinter.
Ich bin ja selbst betroffen;-)
Es ist aber egal, denn der Zug ist nicht aufzuhalten. Anstatt 10 Angestellte, werden mittlerweile Marketingkampagnen von 1-2 in einem Drittel des Zeitaufwands erstellt (oder schneller). Es ist, wie es ist. Das ist nur ein Beispiel von vielen.
Ab hier habe ich alle Folgekommentare gelöscht – ist ist ja bereits angedeutet worden – die Diskussion "deutsches Gejammere" trifft es nicht wirklich – daher führen gegenseitige Beharkungen nicht weiter. Ziel des Beitrags war die Sensibilisierung der Entscheidungsträger (sofern die hier mitlesen), nicht nur auf Buzzwords aufzuspringen, sondern sich über die Sicherheitsimplikationen Gedanken zu machen.
30€ Kosten für KI Plan anstelle 7000€ Kosten für eine IT Stelle: da interessieren "Sicherheitsimplikationen" nicht. Das Einsparpotential ist so dermaßen groß, dass an KI in Unternehmen überhaupt kein Weg vorbeiführt.
In der Hybridwelt hast Du so oder so schon genügend Anschluss an unkontrollierbare Systeme, der Zug, die Kontrolle zu behalten, ist längst abgefahren.
Eine fatal naive Einstellung…
es muss ja keiner Cloud nutzen, ich würde auch dringend davon abraten, aber die Kunden wollen halt.
Wer so denkt — oder rechnet — soll meiner Meinung nach völlig zurecht eine massive Bruchlandung hinlegen.
Wer KI auf einem bestimmten Gebiet nutzt, sollte auf diesem Gebiet schon reichlich Erfahrung haben, um
a) der KI sein Problem möglichst detailliert, mit Fachbegriffen sinnvoll zu erläutern bzw. ihr die Aufgabe korrekt und detailliert zu stellen
b) das Ergebnis oder die Vorschläge der KI verstehen und einordnen zu können.
Das was Du da schreibst klingt nach "was brauch ich die IT-ler noch, das mach ich (als BWLer) für quasi Umme mit Hilfe von KI ab sofort alles selber".
Dann bitte, sollen sie mal so machen. Ich prophezeie bzw. bin sicher: das geht schief, und zwar sowas von. Die KI kann nämlich ganz schön doof sein bzw. entsprechend doofe Vorschläge machen.
bei guten und effektiven ITlern ist die Rechnung nicht ganz so einfach, aber bei Jobs wie Webdesign, Coding im Allgemeinen, Creative und auch marketing ist es genau so. Für 6970€/Monat kann man sich eine Menge Tiral&Error erlauben. Es geht um Kosten/Nutzen Rechnung. Bei Anwälten/Steuerberatern ist es ebenfalls so, KI ist da schon stramm auf dem Vormarsch. Das unterscheidet uns eben auch drastisch von den Amis, deswegen hinken wir technologisch ja auch fast 2 Jahrzehnte zurück: es wird probiert, Fehler erkannt und verbessert. KI arbeitet nicht anders und heute sind Fehlversuche damit dann eben billiger als mit menschlichem Personal (die auch Fehler machen, vor allem nach der Mittagspause).
Was haben diese Leute eigentlich vorher gemacht, wenn sie jetzt ausreichend Zeit oder Zeit im Überfluss haben, um sich jede Menge Trial & Error leisten zu können?
Kann es sein, dass bei den Falschen gespart werden soll bzw. dass überbezahlte MINT-Versager meinen, sie können die aus ihrer Sicht viel zu teuren Experten jetzt einsparen und deren Salär auch noch in die eigene Tasche lenken?
Das suggeriert anscheinend die Marketing-Abteilung der KI-Hersteller.
im Marketing arbeiten keine MINTler, bei Steuerberatern oder Versicherern auch nicht.
Wir brauchen gute Prompter mit guter Allgemeinbildung und Menschenverstand, Expertenwissen wird zurückgedrängt werden.
KI schafft das, was Maschinen früher schafften: die Knappheit an Muskelkraft besiegen, KI macht dies beim Zugang und Verfügbarkeit zu Expertenwissen.
Dies ist nun auf Knopfdruck verfügbar und die agentenbasierten Möglichkeiten schaffen die Disruption nur noch viel schneller, als es bei Maschinen der Fall war.
wie Jack68 schon schrieb. Ein ziemlich schlechter Trollbeitrag. Bitte löschen, das zerstört die Diskussionskultur.
+1