
 Kurze Information für Blog-Leser und -Leserinnen, deren Unternehmen Produkte wie Jira oder Confluence von Atlassian verwenden. Die "Strategen" sind hingegangen und haben ihre AGB geändert. Ab dem 17. August 2026 will Atlassian Kundenmetadaten und In-App-Inhalte standardmäßig aus Jira, Confluence und anderen Cloud-Produkten erfassen, um damit seine KI-Modelle zu trainieren. Wer als Nutzer das nicht möchte, muss das per Opt-out mitteilen.
Kurze Information für Blog-Leser und -Leserinnen, deren Unternehmen Produkte wie Jira oder Confluence von Atlassian verwenden. Die "Strategen" sind hingegangen und haben ihre AGB geändert. Ab dem 17. August 2026 will Atlassian Kundenmetadaten und In-App-Inhalte standardmäßig aus Jira, Confluence und anderen Cloud-Produkten erfassen, um damit seine KI-Modelle zu trainieren. Wer als Nutzer das nicht möchte, muss das per Opt-out mitteilen.
Ich bin am gestrigen 20. April 2026 auf diverse Tweet gestoßen, die diesen Sachverhalt aufgegriffen haben. Nachfolgender Tweet greift die Information auf, verweist aber auf einen Tweet aus 2023.
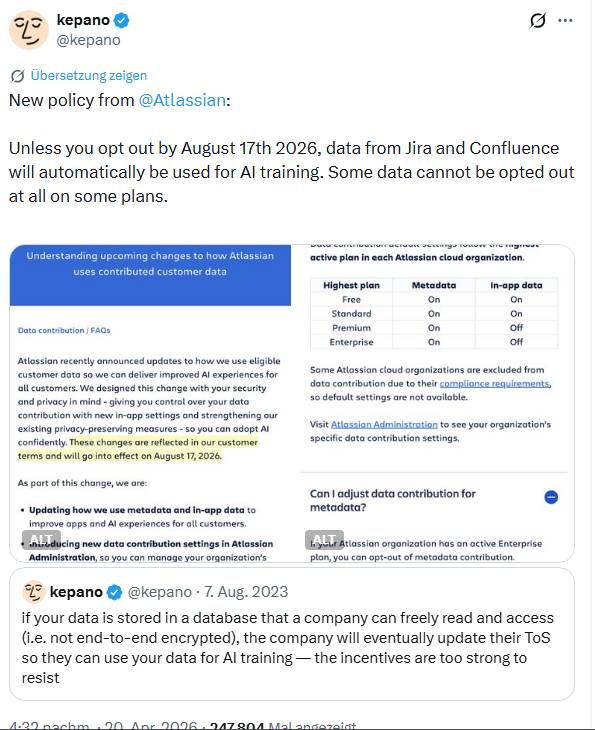
Bereits im August 2023 wies kepano darauf hin, dass Kunden Daten unverschlüsselt in einer Datenbank, die von Atlassian gelesen werden kann, ablegen. Es gibt dort bereits den Hinweis "und damit hat Atlassian die Möglichkeit, die Daten zum AI-Training zu verwenden, die brauchen nur die Terms of Service zu ändern …". Und genau das ist nun passiert.
Laut diesem Artikel ändert Atlassian seine Richtlinien zur Datenbereitstellung, sodass das Unternehmen ab dem 17. August 2026 Kundenmetadaten und In-App-Inhalte aus Jira, Confluence und anderen Atlassian-Cloud-Produkten zum Trainieren seiner KI-Funktionen, darunter „Rovo" und „Rovo Dev", verwenden kann.
- Metadaten umfassen anonymisierte Signale wie Lesbarkeits- und Komplexitätswerte, Aufgabenklassifizierungen, Metriken zur semantischen Ähnlichkeit, Story Points, Sprint-Enddaten und SLA-Werte aus Jira Service Management.
- In-App-Daten umfassen benutzergenerierte Inhalte: Seitentitel und -inhalte in Confluence, Titel von Jira-Issues, Beschreibungen, Kommentare, benutzerdefinierte Emoji-Namen, benutzerdefinierte Statusnamen und Workflow-Namen.
Atlassian gibt an, dass es direkte Identifikatoren entfernen, Daten aggregieren und Schutzmaßnahmen anwenden werde, bevor diese für das Training verwendet werden.
Nutzer müssen explizit ein Opt-out wählen, um die Verwendung der Daten zum Training abzulehnen – wobei laut obigem Tweet einige Daten nicht per Out-out vom Training ausgenommen werden können. In-App-Daten werden innerhalb von 30 Tagen nach Opt-out oder Löschung entfernt, und alle auf diesen Daten trainierten Modelle werden innerhalb von 90 Tagen neu trainiert, um den Beitrag zu löschen.
Die Änderung betrifft etwa 300.000 Kunden und sieht gestaffelte Standardeinstellungen vor: Kunden mit niedrigeren Tarifen können die Erfassung von Metadaten nicht ablehnen, während Enterprise-Kunden weiterhin die Möglichkeit haben, sich dagegen zu entscheiden. Atlassian speichert die bereitgestellten Daten bis zu sieben Jahre lang.









Habe ich das richtig verstanden, dass dies momentan "nur" die Cloud Services betrifft – oder ist das auch bei den On-Prem Versionen.
Um ehrlich zu sein, natürlich stört mich so etwas extrem. Gerade Confluence Artikel und Jira Tickets unterliegen oft sehr sensiblen internen Daten.
Um realistisch zu sein, vermutlich wird über kurz oder lang, jedes Cloud Angebot – das zumindest im Ansatz LLMs verwendet, diese Daten auch zum Training verwenden wollen. Vor allem wenn sie zu Spezialisten in einem Bereich sind oder werden wollen.
Gerade bei Monopolartigen Anbietern, wird man da kaum rauskommen. Daher 3x überlegen ob man sich an ein Cloudservice binden möchte.
OnPrem gibts doch bei denen garnicht mehr.
Ja keine neuen Versionen und Features. Aber man konnte mit einer eigenen Datenbank ein eigenes Data Center einrichten. Ist halt wie immer wenn es keine Updates mehr gibt… eine zwiegespaltene Angelegenheit.
Aber ich bin da auch nicht kompetent und kenne mich zu wenig in dem Thema aus. Ich weiß nur, dass manche es noch OnPrem betreiben.. bzw. betrieben haben… vor wenigen Jahren.. (also nach 2024)
Von https://www.atlassian.com/licensing/data-center-end-of-life :
End of life for impacted Data Center products* will take place on March 28, 2029 at 23:59 PST. Data Center subscriptions and any associated Marketplace apps will expire on this date, making Data Center products and apps read-only.
We understand this transition will take time for many customers, so we will wind down support over 3 years in phases beginning on March 30, 2026. You will have three years from this date to prepare, test, and migrate from Data Center to Atlassian's cloud platform.
On March 30, 2026 at 23:59 PST, new customers will no longer be able to purchase new Data Center subscriptions or new Marketplace Data Center apps.
To ensure your growing teams are supported as you plan your path to cloud, if you are an existing Data Center customer you can continue to purchase new Data Center subscriptions, Marketplace apps, and subscription expansions until March 30, 2028 at 23:59 PST.
Through March 28, 2029, we will continue to provide the following for Data Center products:
Technical support
Security bug-fixes for critical vulnerabilities
Connectors from Atlassian Data Center products to Atlassian Cloud
Tja,
hätten da doch mal Leute vor Jahren vor solche. Entwicklungen gewarnt. ;-)
Geuß
passend zu diesem Thema: beim Acrobat Reader gibt es einen reg key, um das Hochladen von PDF der für KI Trainingszwecke zu unterbinden.
Ob es in Europa überhaupt passieren würde, weiß ich nicht (angeblich nicht lt. Hersteller).
Mir fällt zu diesem Thema nur "denen traue ich keinen Micrometer über den Weg". Als ich 2024 erstmals über das Thema KI-Training beim Adobe Reader hier im Blog berichtete und einen Registrierungsschlüssel zum Opt-out für Windows nannte, hatte ich 24-Stunden später die Aufforderung einer Agentur, die Beitrag "wegen Falschdarstellung" aus dem Blog zu nehmen. Hab ich nicht getan, sondern den Beitrag drei Mal gelesen, es auf eine Auseinandersetzung mit Adobe ankommen lassen, und das Ganze im Beitrag Deaktiviert das Scannen von Dokumenten durch Adobe AI-Lösungen dokumentiert. Und ja, ich wurde auch schon mal Opfer des Digital Millennium Copyright Act (DMCA) (siehe Twitter-Account wegen Berichterstattung zu Adobe-Problemen per DMCA gesperrt). Wer so arbeitet, bekommt bei mir schlicht Null Vertrauenskredit.
da sind wir schon bei Nanometer.
Übel, was man (schlecht dokumentiert) an Schaltern für den Reader findet, aktuelle ADMX stellen die schon mal gar nicht mehr bereit.
Darunter gab es tatsächliche eine Option zum aktiven Upload, das fand ich schon krass. Laut Selbstauskunft, würde es aber in Europa nicht verwendet.
Soweit es geht, wurde der Reader aus Unternehmen restlos verbannt.
Twitter: ist doch gut, das X nun anders tickt (in dieser Hinsicht).
Als Admin einer Atlassian cloud Premiuminstanz wurde ich auch von atlassian kontaktiert. Bei uns ist per default aber schon das opt-out gesetzt und die Email weist darauf hin, dass man das rückgängig machen kann, wenn man das will. Was ich ausnahmsweise mal positiv werte, bei dem ganzen Rest was Atlassian einem so aufbrummt.
Alles, was Du in fremde Hände gibst, kann missbraucht werden. Ob es anonymisiert oder pseudonymisiert weitergegeben wird oder ohne beides — Du kannst es nicht beeinflussen.
Die großen Player machen das alle; was sie haben, verwenden sie zu ihren Zwecken, die sich nicht unbedingt mit denen der "Kunden" decken und die laut AGB und Richtlinie xyz eigentlich ausgeschlossen sind. Das geht denen am (_|_) vorbei, es fällt in den meisten Fällen ohnehin nicht auf, und falls doch einmal, war's eben ein Mitarbeiter, der falsch gespielt oder gepennt hat.
Der Sinn des Datensammelns war nie allein das haben, es geht und ging schon immer um die Verwendung, ums Wissen. Und wenn die Leuten denen das freiwillig zur Verfügung stellen, wären sie ganz schön blöde, sich diese Chance entgehen zu lassen. Und blöde sind die ganz und gar nicht.